数据结构预备知识
本文最后更新于:2022年7月26日 下午
一、C语言常识
- C程序规定一个程序中有一个或多个函数,他们是C程序的基本模块。但必须有且只有一个main函数。
- C程序的执行将从main函数开始,到main函数结束而停止。
- main()是一个函数的名字,括号里面的void表示空的,这里指不接受任何参数。
- 只需要把int和void看作是用来定义main()函数的标准即可
1 | |
C语言的重要性就不多说,学习编程,实践很重要,学校OJ的网址ZZULIOJ,咱们学校考研复试也要C语言上机,重点就是前200道题。比如题目编号1000,整数a+b,最简单入门的一道题,计算两个整数的和。
1 | |
注意到scanf读入数据的时候需要加&取地址符,而printf输出数据的时候却不用,想一想为什么?
因为scanf要往你的变量里写入数值,所以他必须知道那个变量的地址,至于变量里存的是什么值,他是不管的,反正他写入之后就被覆盖成新的值了
对比printf,他是要输出变量里的数值,他只管要那个值,至于地址在哪,他也无所谓
这就是写和读的本质性区别,写只要地址,读只要值
变量其实同时有地址和值两个东西,我们一般用一个变量,都是直接写一个名字,其实如果这个名字在赋值号右边,就是代表值,如果在赋值号左边,就是代表地址,写出来一样,意义是不一样的,编译器自动帮你选择了正确的意义
变量名字写在函数参数里面时,和写在赋值号右边一样,也是代表值,可是像scanf这种函数,他确实需要地址,编译器只认识赋值号,不认识scanf,没法自动选到正确的东西,这时就需要你手动加一个取地址的符号&,明确告诉编译器去选择变量的地址给这个scanf来用。
关于地址或指针的知识,后面也会详细介绍。
For循环
1 | |
1 | |
它的运行过程为:
先执行“表达式1”。
再执行“表达式2”,如果它的值为真(非0),则执行循环体,否则结束循环。
执行完循环体后再执行“表达式3”。
重复执行步骤 2) 和 3),直到“表达式2”的值为假,就结束循环。
上面的步骤中,2) 和 3) 是一次循环,会重复执行,for 语句的主要作用就是不断执行步骤 2) 和 3)。
“表达式1”仅在第一次循环时执行,以后都不会再执行,可以认为这是一个初始化语句。“表达式2”一般是一个关系表达式,决定了是否还要继续下次循环,称为“循环条件”。“表达式3”很多情况下是一个带有自增或自减操作的表达式,以使循环条件逐渐变得“不成立”。
二、数组
把数据放入内存,必须先要分配内存空间。放入4个整数,就得分配4个int类型的内存空间:
1 | |
这样,就在内存中分配了4个int类型的内存空间,共 4×4=16 个字节,并为它们起了一个名字,叫a。
访问数组元素的格式为:
1 | |
index 为数组下标。注意 index 的值必须大于等于零,并且小于数组长度,否则会发生数组越界,出现意想不到的错误,
当赋予数组的元素个数超过数组长度时,就会发生溢出(Overflow)。如下所示:
1 | |
数组长度为3,初始化时却赋予5个元素,超出了数组容量,所以只能保存前3个元素,后面的元素被丢弃。
1 | |
- 数组是一个整体,它的内存是连续的;也就是说,数组元素之间是相互挨着的,彼此之间没有一点点缝隙。
- 一般情况下,数组名会转换为数组的地址,需要使用地址的地方,直接使用数组名即可
- 数组中的每个元素都有一个序号,这个序号从0开始,而不是从1开始,称为下标(Index)
- 数组中每个元素的数据类型必须相同,对于
int a[4];,每个元素都必须为 int。
1 | |

1 | |
在C语言中,字符串总是以'\0'作为结尾,所以'\0'也被称为字符串结束标志,或者字符串结束符。
"abc123"看起来只包含了 6 个字符,我们却将 str 的长度定义为 7,就是为了能够容纳最后的'\0'。如果将 str 的长度定义为 6,它就无法容纳'\0'了
三、C语言指针
1.数据类型
1.1 为什么要用数据类型?
答:数据类型用来说明数据的类型,确定了数据的解释方式,让计算机和程序员不会产生歧义
因为对于不同的对象,不同的数据类型更具有代表性
为了合理地利用空间, 将数据分为多种数据类型
基本类型:char short int long float
1.2 为什么int占4个字节?(32位)
答:可以说是微软规定好的,一个字节(byte)等于8位bit,因为计算机只认识0和1,所以一个字节的长度为2的八次方,
4个字节就是2的32次方 所以最大值为2的32次方-1=4294967295
1.3 int数据类型的取值范围是多少?
答:32位无符号整数 , 其表示范围是2的32次方,最大整数为 2的32次方-1,(最小数是32位每一位都是0,因此减1)
有符号数则要去除一个符号位,正数最大为2的31次方-1 , 负数最小为负 2的31次方
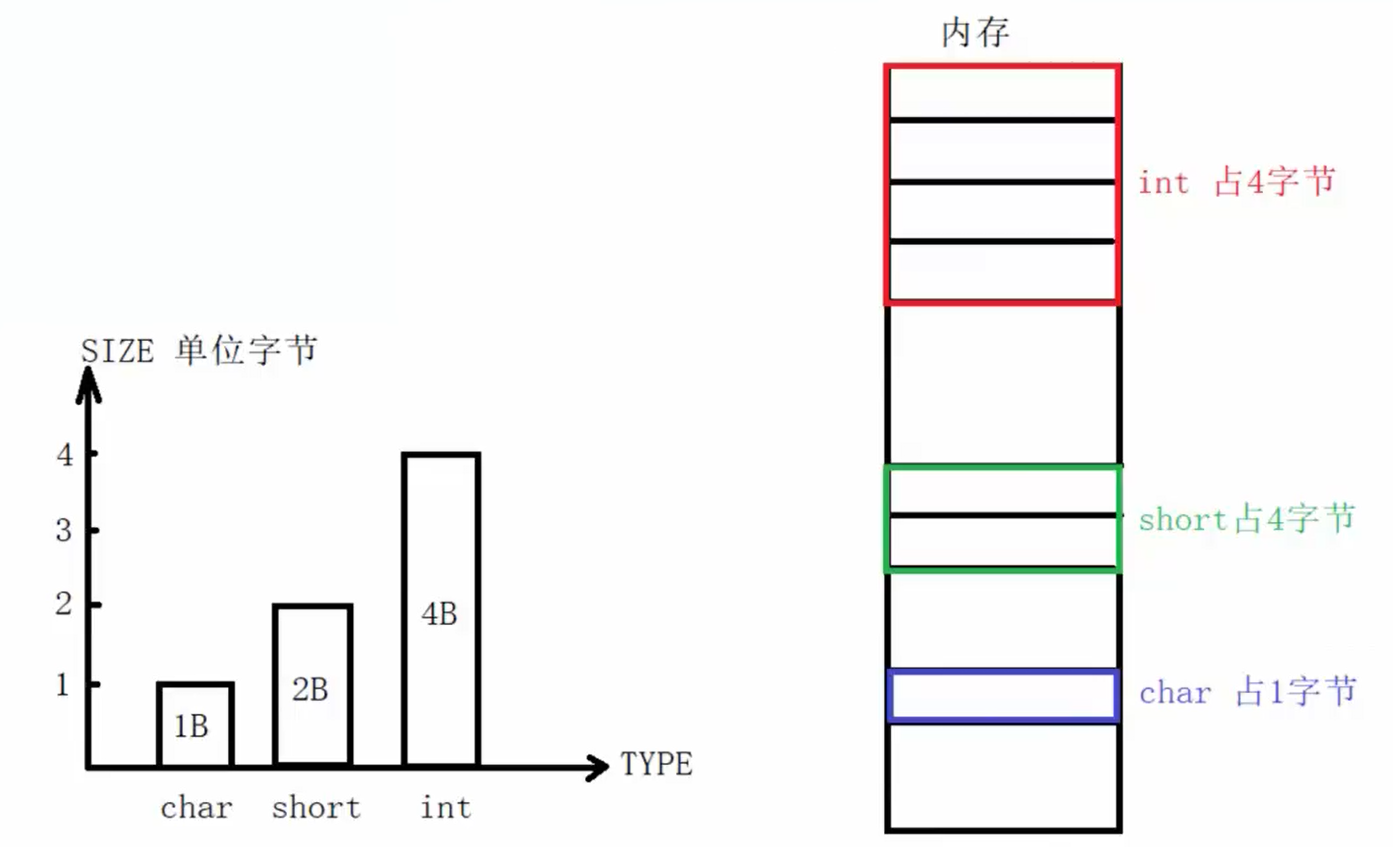
1.4 数据类型长度 sizeof()运算符
1 | |
1 | |
数据类型占内存的位数实际上与操作系统的位数和编译器(不同编译器支持的位数可能有所不同)都有关,具体某种数据类型占字节数得编译器根据操作系统位数两者之间进行协调好后分配内存大小。具体在使用的时候如想知道具体占内存的位数通过**sizeof(int)**可以得到准确的答案
1B = 8b 一个小b只能存放0或1
2. 内存
2.1 内存是什么?
2.2 为什么计算机需要内存?
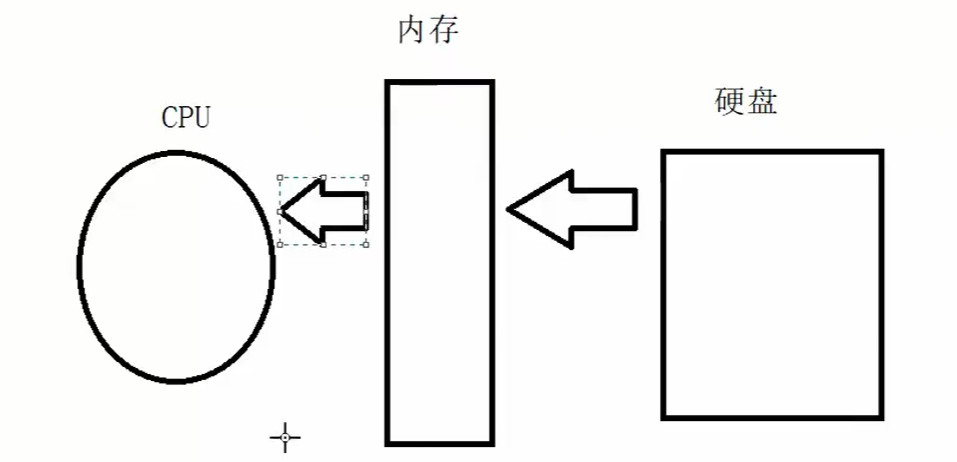
那是因为计算机上的CPU中央处理器需要不断处理电脑硬盘上的数据,
但是CPU速度太快,动辄几Ghz,而硬盘速度太慢,传输速度才不到200mb/s,延迟还大,即使是固态硬盘也差的很远,完全无法跟上CPU的处理速度,这样必然会导致性能下降。
于是工程师就在cpu中设计了缓存,一二三级缓存充当了数据临时仓库的作用,而且速度很快,但是受限于成本和CPU面积,这个缓存空间很有限,根本放不开多少数据,于是就在CPU缓存和硬盘之间又加入了新的存储器:内存。
2.3 内存地址
内存的管理:将内存抽象成一个很大的一维数组
对内存中每一个字节分配一个32位或64位的编号(与32位或64位处理器有关)
这个编号我们称之为内存地址

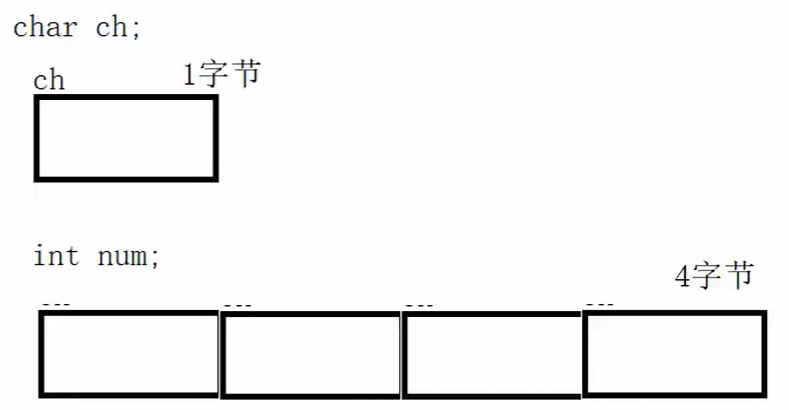
char:占一个字节,分配一个地址
int:占四个字节,分配四个地址
2.4 为什么内存地址以字节为单位?
根据内存的物理结构,因为在内存中最小单位就是字节。所以操作系统在管理它的时候,最小单位也就是字节了
3. C语言指针
计算机中所有的数据都必须放在内存中运行,不同类型的数据占用的字节数不一样,例如 int 占用 4 个字节。为了正确地访问这些数据,必须为每个字节都编上号码。
下图是 4G 内存中每个字节的编号(以十六进制表示):
这内存中字节的编号称为地址(Address)或指针(Pointer)。地址从 0 开始依次增加。
对于 32 位环境,程序能够使用的内存为 4GB,最小的地址为 0,最大的地址为 0XFFFFFFFF。我们来验证一下为什么是4G。
下面是内存单位的一些进制转换:
1 | |
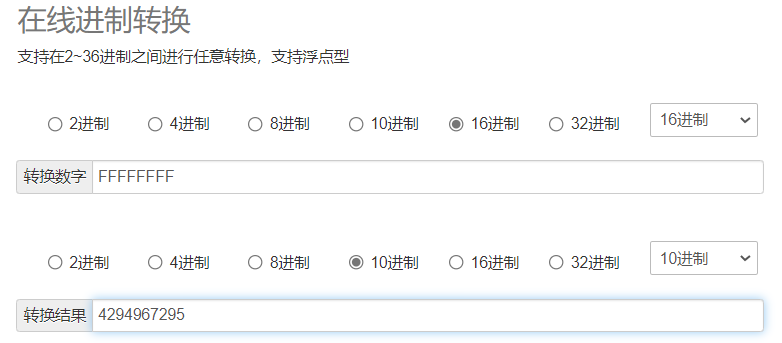
可以看到16进制的FFFFFFFF转换为十进制为4294967295,再加上全0,一共是4294967296个字节
而4G = 4*1024M = 4*1024*1024K =4*1024*1024*1024byte(字节)=4294967296 byte (字节)刚好相等,所以说对于 32 位环境,程序能够使用的内存为 4GB
下面的代码演示了如何输出一个地址:
1 | |
运行结果:
0X60FEEC, 0X60FED8
%#X表示以十六进制形式输出,并附带前缀0X。a 是一个变量,用来存放整数,需要在前面加&来获得它的地址;
str 本身就表示字符串的首地址,不需要加&。
CPU 访问内存时需要的是地址,而不是变量名和函数名!变量名和函数名只是地址的一种助记符,当源文件被编译和链接成可执行程序后,它们都会被替换成地址。编译和链接过程的一项重要任务就是找到这些名称所对应的地址。
假设变量 a、b、c 在内存中的地址分别是 0X1000、0X2000、0X3000,那么加法运算c = a + b;将会被转换成类似下面的形式:
0X3000 = (0X1000) + (0X2000);
( )表示取值操作,整个表达式的意思是,取出地址 0X1000 和 0X2000 上的值,将它们相加,把相加的结果赋值给地址为 0X3000 的内存
变量名和函数名为我们提供了方便,让我们在编写代码的过程中可以使用易于阅读和理解的英文字符串,不用直接面对二进制地址。
需要注意的是,虽然变量名、函数名、字符串名和数组名在本质上是一样的,它们都是地址的助记符。
3.1 指针与指针变量
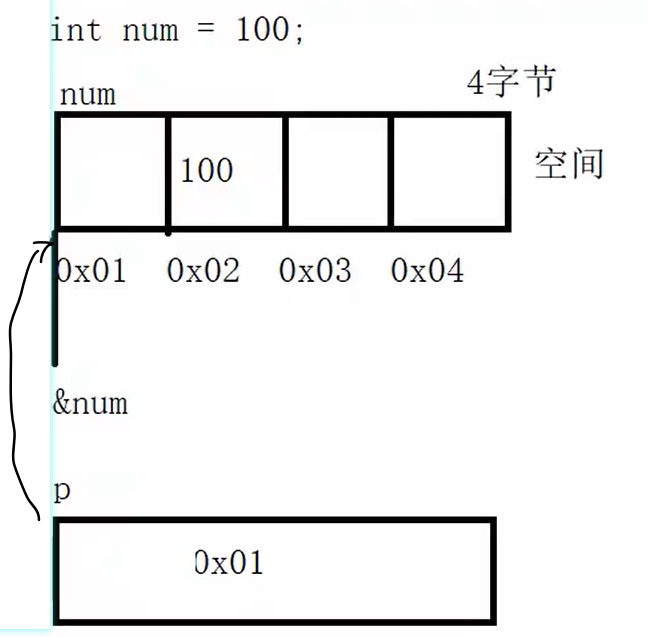
数据在内存中的地址也称为指针,如果一个变量存储了一份数据的指针,我们就称它为指针变量。
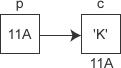
现在假设有一个 char 类型的变量 c,它存储了字符 ‘K’(ASCII码为十进制数 75),并占用了地址为 0X11A 的内存(地址通常用十六进制表示)。另外有一个指针变量 p,它的值为 0X11A,正好等于变量 c 的地址,这种情况我们就称 p 指向了 c,或者说 p 是指向变量 c 的指针。
1.定义指针变量
定义指针变量与定义普通变量非常类似,不过要在变量名前面加星号*,格式为:
1 | |
p1 是一个指向 int 类型数据的指针变量,至于 p1 究竟指向哪一份数据,应该由赋予它的值决定。再如:
1 | |
在定义指针变量 p_a 的同时对它进行初始化,并将变量 a 的地址赋予它,此时 p_a 就指向了 a。值得注意的是,p_a 需要的一个地址,a 前面必须要加取地址符&,否则是不对的。
*是一个特殊符号,表明一个变量是指针变量,定义 p1、p2 时必须带*。而给 p1、p2 赋值时,因为已经知道了它是一个指针变量,就没必要多此一举再带上*,后边可以像使用普通变量一样来使用指针变量。也就是说,**定义指针变量时必须带*,给指针变量赋值时不能带***。
假设变量 a、b、c、d 的地址分别为 0X1000、0X1004、0X2000、0X2004,下面的示意图很好地反映了 p1、p2 指向的变化:
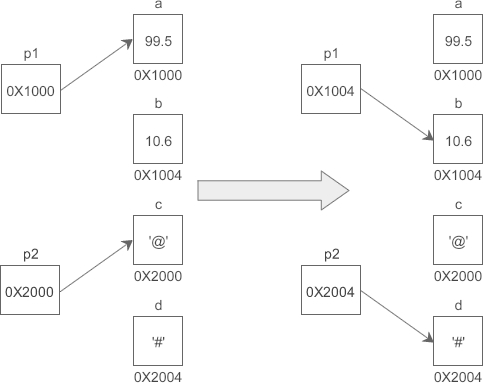
需要强调的是,**p1、p2 的类型分别是float*和char***,而不是float和char,它们是完全不同的数据类型,要引起注意。
指针变量也可以连续定义,例如:
1 | |
注意每个变量前面都要带*。如果写成下面的形式,那么只有 a 是指针变量,b、c 都是类型为 int 的普通变量:
1 | |
2.通过指针变量取得数据
指针变量存储了数据的地址,通过指针变量能够获得该地址上的数据,格式为:
*p;
这里的*称为指针运算符,用来取得某个地址上的数据,请看下面的例子:
1 | |
运行结果:
15, 15
假设 a 的地址是 0X1000,p 指向 a 后,p 本身的值也会变为 0X1000,p 表示获取地址 0X1000 上的数据,也即变量 a 的值。从运行结果看,p 和 a 是等价的。
虽然通过 *p 和 a 获取到的数据一样,但它们的运行过程稍有不同:a 只需要一次运算就能够取得数据,而 *p 要经过两次运算,多了一层“间接”。
假设变量 a、p 的地址分别为 0X1000、0XF0A0,它们的指向关系如下图所示:
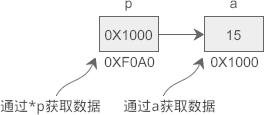
程序被编译和链接后,a、p 被替换成相应的地址。使用 *p 的话,要先通过地址 0XF0A0 取得变量 p 本身的值,这个值是变量 a 的地址,然后再通过这个值取得变量 a 的数据,前后共有两次运算;而使用 a 的话,可以通过地址 0X1000 直接取得它的数据,只需要一步运算。
指针除了可以获取内存上的数据,也可以修改内存上的数据,例如:
1 | |
运行结果:
99, 99, 99, 99
*p 代表的是 a 中的数据,它等价于 a,可以将另外的一份数据赋值给它,也可以将它赋值给另外的一个变量。
*在不同的场景下有不同的作用:*可以用在指针变量的定义中,表明这是一个指针变量,以和普通变量区分开;使用指针变量时在前面加*表示获取指针指向的数据,或者说表示的是指针指向的数据本身。
也就是说,定义指针变量时的*和使用指针变量时的*意义完全不同。以下面的语句为例:
1 | |
第1行代码中*用来指明 p 是一个指针变量,第2行代码中*用来获取指针指向的数据。
【示例】通过指针交换两个变量的值。
1 | |
运行结果:
a=100, b=999
a=999, b=100
3.关于 * 和 &
已知有一个 int 类型的变量 a,pa 是指向它的指针.
*&a 可以理解为*(&a),&a表示取变量 a 的地址(等价于 pa),*(&a)表示取这个地址上的数据(等价于 *pa),绕来绕去,又回到了原点,*&a仍然等价于 a。
&*pa 可以理解为&(*pa),*pa表示取得 pa 指向的数据(等价于 a),&(*pa)表示数据的地址(等价于 &a),所以&*pa等价于 pa。
对星号*的总结
- 表示乘法,例如
int a = 3, b = 5, c; c = a * b; - 表示定义一个指针变量,以和普通变量区分开,例如
int a = 100; int *p = &a;。 - 表示获取指针指向的数据,是一种间接操作,例如
int a, b, *p = &a; *p = 100; b = *p;。
3.2 指针变量续
编号(地址):内存中每一个字节分配一个号码
定义一个变量 存放这个号码,这个变量就叫指针变量
1 | |
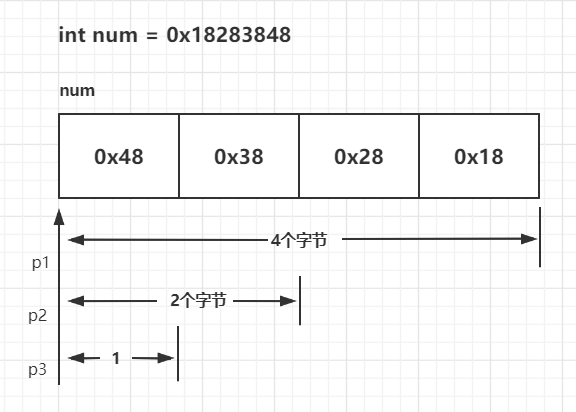
指针变量两种类型
1.自身的类型
2.指向的类型
指针变量指向类型的作用:决定了指针变量所取空间内容的宽度,决定了指针变量+1所跳过的单位跨度
1 | |
指针变量的运算
指针变量保存的是地址,而地址本质上是一个整数,所以指针变量可以进行部分运算,运算,例如加法、减法、比较等。
1 | |
运行结果:
1 | |
从运算结果可以看出:pa、pb、pc 每次加 1,它们的地址分别增加 4、8、1,正好是 int、double、char 类型的长度;减 2 时,地址分别减少 8、16、2,正好是 int、double、char 类型长度的 2 倍。
指针变量加减运算的结果跟数据类型的长度有关,而不是简单地加 1 或减 1
指针变量除了可以参与加减运算,还可以参与比较运算。当对指针变量进行比较运算时,比较的是指针变量本身的值,也就是数据的地址。如果地址相等,那么两个指针就指向同一份数据,否则就指向不同的数据。
上面的代码(第一个例子)在比较 pa 和 paa 的值时,pa 已经指向了 a 的上一份数据,所以它们不相等。而 a 的上一份数据又不知道是什么,所以会导致 printf() 输出一个没有意义的数。
另外需要说明的是,不能对指针变量进行乘法、除法、取余等其他运算,除了会发生语法错误,也没有实际的含义。
指针变量深入
1 | |
4. 数组指针
数组(Array)是一系列具有相同类型的数据的集合,每一份数据叫做一个数组元素(Element)。数组中的所有元素在内存中是连续排列的,整个数组占用的是一块内存。
以int arr[] = { 99, 15, 100, 888, 252 };为例,该数组在内存中的分布如下图所示:

定义数组时,要给出数组名和数组长度,数组名可以认为是一个指针称为数组的首地址。以上面的数组为例,下图是 arr 的指向:

1) 用指针方式遍历数组元素
下面的例子演示了如何以指针的方式遍历数组元素:
1 | |
运行结果:
99 15 100 888 252
2) 用数组指针遍历数组元素
我们也可以定义一个指向数组的指针,例如:
1 | |
arr 本身就是一个指针,可以直接赋值给指针变量 p。arr 是数组第 0 个元素的地址.
所以int *p = arr;也可以写作int *p = &arr[0];。也就是说 arr、p、&arr[0] 等价,它们都指向数组第 0 个元素,或者说指向数组的开头。
数组指针指向的是数组中的一个具体元素,而不是整个数组,所以数组指针的类型和数组元素的类型有关
反过来想,p 并不知道它指向的是一个数组,p 只知道它指向的是一个整数,究竟如何使用 p 取决于程序员的编码。
更改上面的代码,使用数组指针来遍历数组元素:
1 | |
p 只是一个指向 int 类型的指针,编译器并不知道它指向的到底是一个整数还是一系列整数(数组)
更改上面的代码,让 p 指向数组中的第二个元素:
1 | |
运行结果:
99, 15, 100, 888, 252
3) 访问数组指针的两种方式
引入数组指针后,我们就有两种方案来访问数组元素了,一种是使用下标,另外一种是使用指针。
1) 使用下标
也就是采用 arr[i] 的形式访问数组元素。如果 p 是指向数组 arr 的指针,那么也可以使用 p[i] 来访问数组元素,等价于 arr[i]。
比如下面的代码:
1 | |
2) 使用指针
也就是使用 *(p+i) 的形式访问数组元素。另外数组名本身也是指针,也可以使用 *(arr+i) 来访问数组元素,它等价于 *(p+i)。
不管是数组名还是数组指针,都可以使用上面的两种方式来访问数组元素。不同的是,数组名是常量,它的值不能改变,而数组指针是变量(除非特别指明它是常量),它的值可以任意改变。也就是说,数组名只能指向数组的开头,而数组指针可以先指向数组开头,再指向其他元素。
更改上面的代码,借助自增运算符来遍历数组元素:
1 | |
运行结果:
99 15 100 888 252
4) 关于数组指针的思考题
*假设 p 是指向数组 arr 中第 n 个元素的指针,那么 p++、++p、(p)++ 分别是什么意思呢?
*p++ 等价于 *(p++),表示先取得第 n 个元素的值,再将 p 指向下一个元素。
***++p** 等价于 *(++p),会先进行 ++p 运算,使得 p 的值增加,指向下一个元素,整体上相当于 *(p+1),所以会获得第 n+1 个数组元素的值。
**(p)++* 就非常简单了,会先取得第 n 个元素的值,再对该元素的值加 1。假设 p 指向第 0 个元素,并且第 0 个元素的值为 99,执行完该语句后,第 0 个元素的值就会变为 100。
5. 字符串指针
下面是字符数组的例子:
1 | |
运行结果:
beijingren
b e i j i n g r e n
用指针的方式来输出字符串:
1 | |
运行结果:
biancheng
biancheng
biancheng
6. 指针变量作为函数参数
交换两个变量的值:
1 | |
运行结果:
a = 66, b = 99
从结果可以看出,a、b 的值并没有发生改变,交换失败。这是因为 swap() 函数内部的 a、b 和 main() 函数内部的 a、b 是不同的变量,占用不同的内存,它们除了名字一样,没有其他任何关系,swap() 交换的是它内部 a、b 的值,不会影响它外部(main() 内部) a、b 的值。
改用指针变量作参数后就很容易解决上面的问题:
1 | |
运行结果:
a = 99, b = 66
调用 swap() 函数时,将变量 a、b 的地址分别赋值给 p1、p2,这样 p1、p2 代表的就是变量 a、b 本身,交换 p1、p2 的值也就是交换 a、b 的值。函数运行结束后虽然会将 p1、p2 销毁,但它对外部 a、b 造成的影响是“持久化”的,不会随着函数的结束而“恢复原样”。
需要注意的是临时变量 temp,它的作用特别重要,因为执行*p1 = *p2;语句后 a 的值会被 b 的值覆盖,如果不先将 a 的值保存起来以后就找不到了。
当然我们也可以使用C++的引用 & ,来实现同样的效果,而且更简单一点:
1 | |
运行结果为:a = 99, b = 66
& 在C语言中是取地址符,这里指C++的引用,注意上面这段代码要在C++程序中才能运行,也就是.cpp文件
7. 用数组作为函数参数
数组是一系列数据的集合,无法通过参数将它们一次性传递到函数内部,如果希望在函数内部操作数组,必须传递数组指针。下面的例子定义了一个函数 max(),用来查找数组中值最大的元素:
1 | |
运行结果:
输入6个元素:12 55 30 8 93 27
Max value is 93!
参数 intArr 仅仅是一个数组指针,在函数内部无法通过这个指针获得数组长度,必须将数组长度作为函数参数传递到函数内部。
数组 nums 的每个元素都是整数,scanf() 在读取用户输入的整数时,要求给出存储它的内存的地址,nums+i就是第 i 个数组元素的地址。
8. 指针作为函数的返回值
C语言允许函数的返回值是一个指针(地址),我们将这样的函数称为指针函数。下面的例子定义了一个函数 strlong(),用来返回两个字符串中较长的一个:
1 | |
9. 函数指针
一个函数总是占用一段连续的内存区域,函数名在表达式中有时也会被转换为该函数所在内存区域的首地址,这和数组名非常类似。我们可以把函数的这个首地址(或称入口地址)赋予一个指针变量,使指针变量指向函数所在的内存区域,然后通过指针变量就可以找到并调用该函数。这种指针就是函数指针。
函数指针的定义形式为:
**returnType (*pointerName)(param list)**;
returnType 为函数返回值类型,pointerName 为指针名称,param list 为函数参数列表。参数列表中可以同时给出参数的类型和名称,也可以只给出参数的类型,省略参数的名称,这一点和函数原型非常类似。
注意( )的优先级高于*,第一个括号不能省略,如果写作returnType *pointerName(param list);就成了函数原型,它表明函数的返回值类型为returnType *。
【实例】用指针来实现对函数的调用。
1 | |
运行结果:
Input two numbers:10 50
Max value: 50
第 14 行代码对函数进行了调用。pmax 是一个函数指针,在前面加 * 就表示对它指向的函数进行调用。注意( )的优先级高于*,第一个括号不能省略。
10. 对C语言指针的总结:
指针(Pointer)就是内存的地址,C语言允许用一个变量来存放指针,这种变量称为指针变量。指针变量可以存放基本类型数据的地址,也可以存放数组、函数以及其他指针变量的地址。
程序在运行过程中需要的是数据和指令的地址,变量名、函数名、字符串名和数组名在本质上是一样的,它们都是地址的助记符:在编写代码的过程中,我们认为函数名、字符串名和数组名表示的是代码块或数据块的首地址;程序被编译和链接后,这些名字都会消失,取而代之的是它们对应的地址。
在我们目前所学到的语法中,星号*主要有三种用途:
- 表示乘法,例如
int a = 3, b = 5, c; c = a * b;,这是最容易理解的。 - 表示定义一个指针变量,以和普通变量区分开,例如
int a = 100; int *p = &a;。 - 表示获取指针指向的数据,是一种间接操作,例如
int a, b, *p = &a; *p = 100; b = *p;
指针变量可以进行加减运算,例如
p++、p+i、p-=i。指针变量的加减运算并不是简单的加上或减去一个整数,而是跟指针指向的数据类型有关。给指针变量赋值时,要将一份数据的地址赋给它,不能直接赋给一个整数,例如
int *p = 1000;是没有意义的,使用过程中一般会导致程序崩溃。使用指针变量之前一定要初始化,否则就不能确定指针指向哪里,如果它指向的内存没有使用权限,程序就崩溃了。对于暂时没有指向的指针,建议赋值
NULL。两个指针变量可以相减。如果两个指针变量指向同一个数组中的某个元素,那么相减的结果就是两个指针之间相差的元素个数。
数组也是有类型的,数组名的本意是表示一组类型相同的数据。在定义数组时,或者和 sizeof、& 运算符一起使用时数组名才表示整个数组,表达式中的数组名会被转换为一个指向数组的指针。
四、结构体
1. C语言结构体
C语言结构体(Struct)从本质上讲是一种自定义的数据类型,只不过这种数据类型比较复杂,是由 int、char、float 等基本类型组成的。你可以认为结构体是一种聚合类型。
在实际开发中,我们可以将一组类型不同的、但是用来描述同一件事物的变量放到结构体中。例如,在校学生有姓名、年龄、身高、成绩等属性,学了结构体后,我们就不需要再定义多个变量了,将它们都放到结构体中即可。
在C语言中,可以使用结构体(Struct)来存放一组不同类型的数据。结构体的定义形式为:
struct 结构体名{
结构体所包含的变量或数组
};
结构体是一种集合,它里面包含了多个变量或数组,它们的类型可以相同,也可以不同,每个这样的变量或数组都称为结构体的成员(Member)。请看下面的一个例子:
1 | |
stu 为结构体名,它包含了 5 个成员,分别是 name、num、age、group、score。结构体成员的定义方式与变量和数组的定义方式相同,只是不能初始化。
注意大括号后面的分号
;不能少,这是一条完整的语句。
结构体也是一种数据类型,它由程序员自己定义,可以包含多个其他类型的数据。
像 int、float、char 等是由C语言本身提供的数据类型,不能再进行分拆,我们称之为基本数据类型;而结构体可以包含多个基本类型的数据,也可以包含其他的结构体,我们将它称为复杂数据类型或构造数据类型。
2. 结构体变量
既然结构体是一种数据类型,那么就可以用它来定义变量。例如:
1 | |
定义了两个变量 stu1 和 stu2,它们都是 stu 类型,都由 5 个成员组成。注意关键字struct不能少。
stu 就像一个“模板”,定义出来的变量都具有相同的性质。也可以将结构体比作“图纸”,将结构体变量比作“零件”,根据同一张图纸生产出来的零件的特性都是一样的。
你也可以在定义结构体的同时定义结构体变量:
1 | |
将变量放在结构体定义的最后即可。
如果只需要 stu1、stu2 两个变量,后面不需要再使用结构体名定义其他变量,那么在定义时也可以不给出结构体名,如下所示:
1 | |
这样做书写简单,但是因为没有结构体名,后面就没法用该结构体定义新的变量。
理论上讲结构体的各个成员在内存中是连续存储的,和数组非常类似,例如上面的结构体变量 stu1、stu2 的内存分布如下图所示,共占用 4+4+4+1+4 = 17 个字节。

但是在编译器的具体实现中,各个成员之间可能会存在缝隙,对于 stu1、stu2,成员变量 group 和 score 之间就存在 3 个字节的空白填充(见下图)。这样算来,stu1、stu2 其实占用了 17 + 3 = 20 个字节。

3. 成员的获取和赋值
结构体和数组类似,也是一组数据的集合,整体使用没有太大的意义。数组使用下标[ ]获取单个元素,结构体使用点号.获取单个成员。获取结构体成员的一般格式为:
结构体变量名.成员名;
通过这种方式可以获取成员的值,也可以给成员赋值:
1 | |
运行结果:
Tom的学号是12,年龄是18,在A组,今年的成绩是136.5!
除了可以对成员进行逐一赋值,也可以在定义时整体赋值,例如:
1 | |
不过整体赋值仅限于定义结构体变量的时候,在使用过程中只能对成员逐一赋值,这和数组的赋值非常类似。
需要注意的是,结构体是一种自定义的数据类型,是创建变量的模板,不占用内存空间;
结构体变量才包含了实实在在的数据,需要内存空间来存储。
4.结构体指针(指向结构体的指针)
4.1 结构体指针
当一个指针变量指向结构体时,我们就称它为结构体指针,C语言结构体指针的定义形式一般为:
struct 结构体名 *变量名;
定义结构体指针的实例:
1 | |
也可以在定义结构体的同时定义结构体指针:
1 | |
注意,结构体变量名和数组名不同,数组名在表达式中会被转换为数组指针,而结构体变量名不会转换为指针,无论在任何表达式中它表示的都是整个集合本身,要想取得结构体变量的地址,必须在前面加&,所以给 pstu 赋值只能写作:
struct stu *pstu = &stu1;
而不能写作:
struct stu *pstu = stu1;
还应该注意,结构体和结构体变量是两个不同的概念:结构体是一种数据类型,是一种创建变量的模板,编译器不会为它分配内存空间,就像 int、float、char 这些关键字本身不占用内存一样;结构体变量才包含实实在在的数据,才需要内存来存储。下面的写法是错误的,不可能去取一个结构体名的地址,也不能将它赋值给其他变量:
struct stu *pstu = &stu;
struct stu *pstu = stu;
4.2 获取结构体成员
通过结构体指针可以获取结构体成员,一般形式为:
(*pointer).memberName
或者:
pointer->memberName
第一种写法中,.的优先级高于*,(*pointer)两边的括号不能少。如果去掉括号写作*pointer.memberName,那么就等效于*(pointer.memberName),这样意义就完全不对了。
第二种写法中,**->是一个新的运算符,习惯称它为“箭头”**,有了它,可以通过结构体指针直接取得结构体成员;
这也是**->在C语言中的唯一用途**。
上面的两种写法是等效的,我们通常采用后面的写法,这样更加直观。
【示例】结构体指针的使用。
1 | |
运行结果:
Tom的学号是12,年龄是18,在A组,今年的成绩是136.5!
Tom的学号是12,年龄是18,在A组,今年的成绩是136.5!
【示例】结构体数组指针的使用。
1 | |
运行结果:
1 | |
4.3 结构体指针作为函数参数
结构体变量名代表的是整个集合本身,作为函数参数时传递的整个集合,也就是所有成员,而不是像数组一样被编译器转换成一个指针。如果结构体成员较多,尤其是成员为数组时,传送的时间和空间开销会很大,影响程序的运行效率。所以最好的办法就是使用结构体指针,这时由实参传向形参的只是一个地址,非常快速。
【示例】计算全班学生的总成绩、平均成绩和以及 140 分以下的人数。
1 | |
运行结果:
sum=707.50
average=141.50
num_140=2
4.4 结构体讲解版本2
可以声明一个指向结构类型对象的指针。
1 | |
请问怎样通过指针 ptr 来访问 ss 的三个成员变量?
答案:
1 | |
又请问怎样通过指针 pstr 来访问 ss 的三个成员变量?
答案:
1 | |
虽然在编译器上调试过上述代码,但是要知道,这样使用 pstr 来访问结构成员是不正规的。
指针与函数的关系
可以把一个指针声明成为一个指向函数的指针。
1 | |
可以把指针作为函数的形参。在函数调用语句中,可以用指针表达式来作为实参。
1 | |
这个例子中的函数fun统计一个字符串中各个字符的ASCII码值之和。
数组的名字也是一个指针。在函数调用中,当把 str作为实参传递给形参 s 后,实际是把 str 的值传递给了 s,s 所指向的地址就和 str 所指向的地址一致
但是 str 和 s 各自占用各自的存储空间。在函数体内对 s 进行自加 1 运算,并不意味着同时对 str 进行了自加 1 运算。
五、C语言typedef的用法
typedef:C语言允许为一个数据类型起一个新的别名,就像给人起“绰号”一样。起别名的目的不是为了提高程序运行效率,而是为了编码方便。
一个结构体的名字是 stu,要想定义一个结构体变量就得这样写:
struct stu stu1;
struct 看起来就是多余的,但不写又会报错。如果为 struct stu 起了一个别名 STU,书写起来就简单了:
STU stu1;
使用关键字 typedef 可以为类型起一个新的别名。typedef 的用法一般为:
typedef oldName newName;
oldName 是类型原来的名字,newName 是类型新的名字。例如:
1 | |
1 | |
typedef的最常用的作用就是给结构体变量重命名:
1 | |
可以看到typedef可以为关键词改名,使改名之后的INFO类型等价于struct _INFO类型,让我们在定义这种结构类型时更方便、省事。
六、内存操作函数
在 C 语言中,程序中 malloc 等内存分配函数的使用次数一定要和 free 相等,并一一配对使用。绝对要避免“malloc 两次 free 一次”或者“malloc 一次 free 两次”等情况。
在 free 之后必须为指针赋一个新值
在使用指针进行动态内存分配操作时,在指针 p 被 free 释放之后,指针变量本身并没有被删除。如果这时候没有将指针 p 置为 NULL,会让人误以为 p 是个合法的指针而在以后的程序中错误使用它。
“free(p)”释放的是指针变量 p 所指向的内存,而不是指针变量 p 本身。指针变量 p 并没有被释放,仍然指向原来的存储空间。
其实,指针只是一个变量,只有程序结束时才被销毁。释放内存空间后,原来指向这块空间的指针还是存在的,只不过现在指针指向的这块内存是不合法的。因此,在释放内存后,必须把指针指向 NULL,以防止指针在后面不小心又被解引用了。
七、C++引用 &
C++ 参数传值
1 | |
上面是一段C++ 的语法,运行结果为:
After swaping: a = 4 b = 5
对C++语法不熟悉的话,可以看下面C语言的语法,是一样的效果
1 | |
上面代码运行结果为:
后:a = 4, b = 5
C++参数传引用 & 对参数的修改结果带回来
1 | |
因为C++是兼容C语言,所以可以写下面的代码,在C语言中使用C++ 的引用,也就是在变量前加&,但是必须在(.cpp)也就是C++文件中运行。
1 | |
运行结果为:n1=50, n2= 100
可以看到结果,使用引用&后,对参数的修改可以带回来
当然C语言也可以用指针来实现,但是不太方便,代码如下:
1 | |
对C++引用了解到这里即可,下面的介绍还涉及到C++的语法
C++引用
引用是 C++ 的新增内容,在实际开发中会经常使用;C++ 用的引用就如同C语言的指针一样重要,但它比指针更加方便和易用,有时候甚至是不可或缺的。
同指针一样,引用能够减少数据的拷贝,提高数据的传递效率。
引用的定义方式类似于指针,只是用&取代了*,语法格式为:
type &name = data;
type 是被引用的数据的类型,name 是引用的名称,data 是被引用的数据。引用必须在定义的同时初始化,并且以后也要从一而终,不能再引用其它数据,这有点类似于常量(const 变量)。
下面是一个演示引用的实例:
1 | |
运行结果:
99, 99
0x28ff44, 0x28ff44
本例中,变量 r 就是变量 a 的引用,它们用来指代同一份数据;也可以说变量 r 是变量 a 的另一个名字。从输出结果可以看出,a 和 r 的地址一样,都是0x28ff44;或者说地址为0x28ff44的内存有两个名字,a 和 r,想要访问该内存上的数据时,使用哪个名字都行。
注意,引用在定义时需要添加&,在使用时不能添加&,使用时添加&表示取地址。如上面代码所示,第 6 行中的&表示引用,第 8 行中的&表示取地址。除了这两种用法,&还可以表示位运算中的与运算。
由于引用 r 和原始变量 a 都是指向同一地址,所以通过引用也可以修改原始变量中所存储的数据,请看下面的例子:
1 | |
运行结果:
47, 47
最终程序输出两个 47,可见原始变量 a 的值已经被引用变量 r 所修改。
如果读者不希望通过引用来修改原始的数据,那么可以在定义时添加 const 限制,形式为:
const type &name = value;
也可以是:
type const &name = value;
这种引用方式为常引用
C++引用作为函数参数
在定义或声明函数时,我们可以将函数的形参指定为引用的形式,这样在调用函数时就会将实参和形参绑定在一起,让它们都指代同一份数据。如此一来,如果在函数体中修改了形参的数据,那么实参的数据也会被修改,从而拥有“在函数内部影响函数外部数据”的效果。
至于实参和形参是如何绑定的,我们将在下节中讲解,届时我们会一针见血地阐明引用的本质。
一个能够展现按引用传参的优势的例子就是交换两个数的值,请看下面的代码:
1 | |
运行结果:
Input two integers: 12 34↙
12 34
Input two integers: 88 99↙
99 88
Input two integers: 100 200↙
200 100
本例演示了三种交换变量的值的方法:
swap1() 直接传递参数的内容,不能达到交换两个数的值的目的。对于 swap1() 来说,a、b 是形参,是作用范围仅限于函数内部的局部变量,它们有自己独立的内存,和 num1、num2 指代的数据不一样。调用函数时分别将 num1、num2 的值传递给 a、b,此后 num1、num2 和 a、b 再无任何关系,在 swap1() 内部修改 a、b 的值不会影响函数外部的 num1、num2,更不会改变 num1、num2 的值。
swap2() 传递的是指针,能够达到交换两个数的值的目的。调用函数时,分别将 num1、num2 的指针传递给 p1、p2,此后 p1、p2 指向 a、b 所代表的数据,在函数内部可以通过指针间接地修改 a、b 的值。
swap3() 是按引用传递,能够达到交换两个数的值的目的。调用函数时,分别将 r1、r2 绑定到 num1、num2 所指代的数据,此后 r1 和 num1、r2 和 num2 就都代表同一份数据了,通过 r1 修改数据后会影响 num1,通过 r2 修改数据后也会影响 num2。
从以上代码的编写中可以发现,按引用传参在使用形式上比指针更加直观。在以后的 C++ 编程中,我鼓励读者大量使用引用,它一般可以代替指针(当然指针在C++中也不可或缺),C++ 标准库也是这样做的。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!