图像处理中的抠图技术image matting
本文最后更新于:2022年7月26日 下午
抠图技术(imagematting)
图像处理中的image matting技术,中文简称抠图技术。Image Matting也是一个基本的计算机视觉问题,有着广泛的应用。
证件照换背景应该算是最简单的Image Matting,由于证件照背景属性的特殊性,这个抠图很容易可以实现。算法分为几个步骤:
- 读入原始证件照图片
- 转换到HSV色彩空间(色调(H),饱和度(S),明度(V))
- 设置HSV空间的阈值获得图片背景的mask(抠图的结果)
- 腐蚀膨胀去除干扰点
- 遍历像素点替换背景颜色

使用python+opencv库可以很容易实现,有兴趣的可以自己了解一下
抠图技术与图像分割有什么区别
刚接触这项技术时一直有些疑虑,这个和图像分割技术有什么差别,

然后大概明白。图像分割是将原图分割成若干块,分割的好与不好就看分出来的块是否与图像的内容对应了,例如如果分割结束后某一块只包含半张人脸,另外半张在另一块上,那肯定就不是好的分割了。至于抠图技术,基本只会分成两块,一块是前景,另一块是背景,而大多数时候我们抠图也就是为了把前景给拿出来。基本抠图都要人工交互,而分割技术则是全自动的,当然有人工介入的抠图分割在准确性上要远高于常规的图像分割技术,优秀的抠图算法是有能力将前景中非常细小的毛发细节都能提取出的好算法,这点是传统图像分割技术做不到的。也不少文章会将分割技术作为抠图的第一步融入进去。
抠图技术早期应用
早期这项技术主要被用在电影工业中,所以这是一项古老的技术,只是现在依然在不断发展进步。你有时会看到拍电影的摄影棚都是全绿色背景,以及一群穿着全绿色衣服的工作人员。这些都会在后期的抠图技术下被抠掉换上“真正的”背景,这用的就是最原始的蓝屏抠图技术,即背景是纯色时用的抠图技术,纯色的背景可以确保前景被准确抠出。

不过纯色背景的情况在现实中太少,应用面狭窄,抠图技术重点在背景是自然图像的复杂图片。

复杂图片的image matting
在复杂图片的Image Matting课题上,主要包括经典的传统方法和近年来兴起的深度学习方法。
在传统方法部分,有比较典型的三种经典算法:
Bayesian Matting(贝叶斯抠图)
Closed Form Mating(闭型抠图)
KNN Matting(K近邻抠图)
而在深度学习方面的主要有
Deep Image Matting
AlphaGAN Matting
抠图界的上帝公式
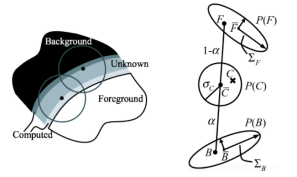
图像或视频中的前景准确估计问题,在实际应用中具有十分重要的意义。它是图像编辑和电影制作中的一项关键技术。虽然这项古老的技术发展至今已经数十年了,但几乎所有的解决方案都是在想办法做成一件事情,把这个公式“C = αF + (1-α)B”给解出来,这个公式就是1996年Alvy Ray Smith等人的《Blue Screen Matting》的paper中正式定义的Image Matting问题提出的,可以把它称为抠图界的“上帝公式”。
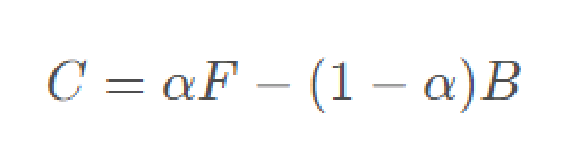
其中C是原始图像的像素(例如下面的左图就是一张待处理的图像),为已知量;α是透明度,F是前景像素(例如图中的人物),B是背景像素(例如图中的树丛),这三个变量为未知量。

对于这个公式的理解,我们可以把原始图像看做是前景和背景按照一定权重(α透明度)叠加组成的。对于完全确定是前景的像素,α = 1;对于完全确定是背景的像素,α=0; 但问题是我们不能100%确定每个像素它是否是属于前景或是背景,如果一个像素一个像素分析后你也确实可以确定哪个属于前景,哪个属于背景,但这时图也已经抠好了,计算机就没用了,这里也就引出了抠图技术真正需要计算机出马的部分了,就是处理在图像中那些人工不是那么容易辨认是前景还是背景的细节部分。不容易确定的部分则为未知区域由计算机处理。对于不确定是前景还是背景的像素,a是介于0到1之间的浮点数。 Image Matting问题研究的是,如何通过C,推测出未知的三个变量α、F和B,难度可想而知。
获取到每个像素的α值后就可以生成一张α图,这张图看起来是只有前景是白的,其余都是黑的,这就像是我们都曾见过的在艺术创作中使用的蒙版(matte),只把前景露出来,其他背景被挡住。它和原图结合后就完成了抠图的工作了。之后只要继续按照上帝公式就可将抠出的前景移到新的背景中了。读入一张新的背景图片(如下图中间所示),并将前景(经由α 矩阵)融合到新的背景中,最终结果如上图右所示。

问题是一个等式解不出三个变量啊?
1996年Alvy Ray Smith等人的《Blue Screen Matting》给出了Triangulation Matting的方法,整体思想是:既然Image Matting原问题那么难,不如把条件放松,使得问题简单一些,假设我知道了 B和 C,那么有没有可能得到 α 和 F,于是作者提出针对同一张前景,切换背景,来应用最小二乘法,计算得到对应的透明度和前景。
2004年Jian Sun等人的《Poisson matting》开始在Image Matting课题上提出使用Trimap作为辅助工具。Trimap分为三种颜色,黑色代表完全背景(此处 α为0),白色代表完全前景(此处 α 为1),灰色代表不确定区域( α为0.5),所以说trimap图就是包含前景、背景和未知区域的图。因为前面提到过由于方程是病态的,所以要有约束条件才有解,而Trimap就相当于约束条件,并且简化计算。自此,Image Matting变为下图所示过程:
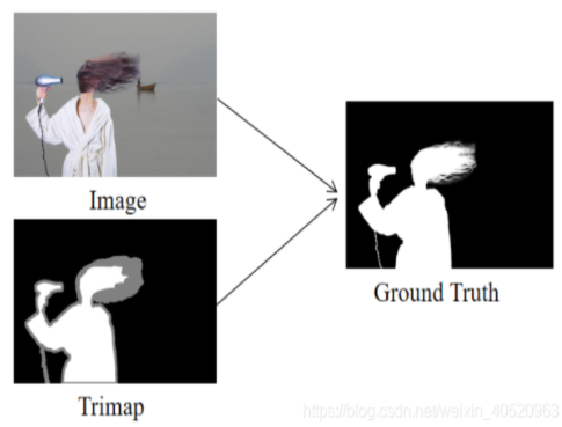
基本上所有在文献中的抠图算法都是在教计算机如何更准确更快地通过用户指定的前景和背景估计出未知区域的α、B、F,而用户指定的方式一般分为两种,一种是这种提到的信息量很大的trimap图,另一种则是信息量具少的草图(scribbles)。然而trimap图的构建是很麻烦的,用户需要几乎把整张图都涂满才行,而草图就方便很多,只要在前景和背景处画几笔即可。所以对草图的处理才是未来抠图技术的发展趋势。

近年来,随着深度学习技术的发展,使得Deep Learning在计算机视觉领域的应用变得越来越广泛。主要介绍2017年CVPR的Deep Image Matting和AlphaGAN。
Deep Image Matting
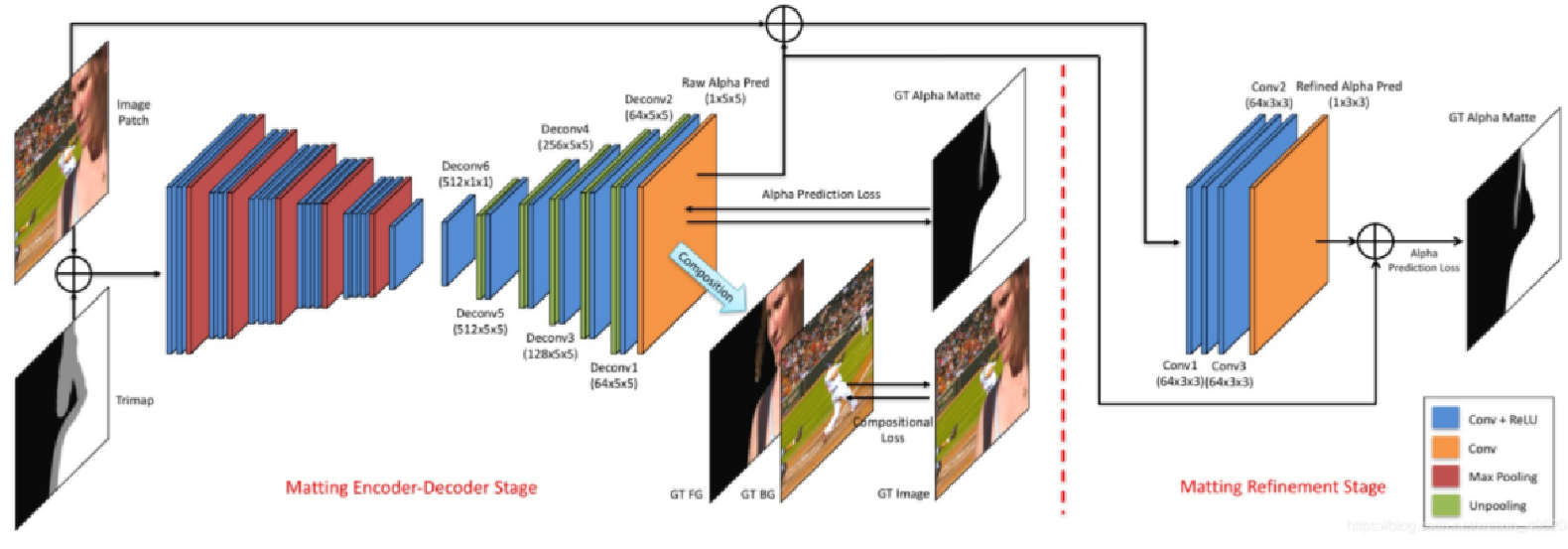
这个网络基于典型的Encoder-Decoder结构,做深度学习的应该比较熟悉这种结构在图像分割和以图得图的GAN(生成对抗网络)网络中最常见。Encoder用pre-trained的VGG16,把fc6从全连接换成了卷积,并在输入增加了第四通道channel4,用来存放输入的trimap,因为channel4而增加的weights全部初始化为0。Decoder用简单的unpooling(上池化)和convolution的组合来做upsampling(上采样)和空间结构推断。右边的refine network是为了解决第一阶段预测输出边缘blur(模糊)的情况。
值得一提的是这篇文章提出了两种Loss,这两种Loss分别是Alpha-prediction Loss和Compositional Loss。
Alpha-prediction Loss即Ground Truth α值和预测每个像素α 值之间的绝对差异。
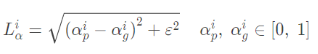
Compositional Loss,即Ground Truth 前景、背景和预测alpha matting组成的预测RGB图片与Ground Truth RGB图片之间的绝对差异。
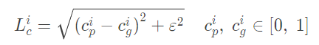
而神经网络训练的Loss是由两种Loss加权,翻
在实验中作者设置 ω l = 0.5 ,即两种Loss的贡献一样。
AlphaGAN
基于前面Deep Image Matting的启发,我们知道Image Matting这个任务本质上是一个以图得图的任务,而处理这种任务最常见的就是图像分割和GAN(生成对抗网络)。这里我们选择接着探究GAN网络在Image Matting问题上的应用。
(生成对抗网络GAN由生成网络G(Generator)和判别网络D(Discriminator)组成。在训练过程中,生成网络G的目标是尽量生成真实的图片去欺骗判别网络D。而D的目标是尽量把G生成的图片和真实的图片区分开来。这样G和D构成了一个动态的“零和博弈”。GAN就是通过Generator和discriminator进行零和博弈,来不断生成,不断欺骗来获得更好的效果。)
2018年BMVC有一篇论文:AlphaGAN。这篇文章是基于前面的Deep Image Matting做的。AlphaGAN matting 很大程度上借鉴了Deep Image matting。
AlphaGAN matting 将Deep Image matting中的深度网络拿来作为了GAN的generator,改进只是只是把encoder中的VGG16换成了ResNet50,并把少部分卷积层替换,采用的损失函数和上面提到的loss一致。AlphaGAN matting 的discriminator采用PatchGAN,也是以图得图问题中比较先进且常用的discriminator (鉴别器)。PatchGAN对图片中每个N×N的小块(Patch)计算概率,然后将这些概率求平均值作为整体的输出,这样做可以加快速度以及加快收敛。
结合显著性检测自动生成Trimap
到目前为止,大家都能看出来Image Matting最大的弊端:给定一张图,需要一张手工标记的trimap才能开始Image Matting。
手动生成trimap
前面提到的Image Matting方法都需要手工标注的Trimap才可以进行抠图。而这些trimap大多依赖手工标记生成,如利用Photoshop (PS)等,但这些专业的图像操作软件对于普通人利用起来并非易事。于是网上也有封装好的Robust Matting程序来协助我们手工标记来生成trimap。
下面我们讨论怎样让trimap的生成变得更加智能。
自动生成trimap
我们想到用显著图(saliency map)结合一些图像处理方法来实现从原始图片到trimap,再从trimap到图。从而实现只需要给定一张原始图片,就可以输出抠完图的结果。
算法流程:
1利用目前比较先进的显著物体检测算法(salient object detection)来得到显著图。
2对显著图进行阈值分割,粗略地划分前景区域和背景区域。
3对得到的二值图分别进行一次腐蚀和一次膨胀操作。
4两次操作的差记为未知区域。
5由前景区域、背景区域、未知区域生成trimap。
实验结果
在对标准数据集的图片进行测试后,我们采用自己找来的图片来提取trimap后利用之前提到的四种方法进行抠图,实验效果如下图所示,相关结果也比较优秀。

最后是我们提出的利用显著性检测来实现对一些图片生成trimap的结果展示,可以看出在一些显著性比较明显的图片上,trimap生成也还不错:

贝叶斯抠图
引言
这里要讲的paper是2001年CVPR上的文献:《A Bayesian Approach to Digital Matting》。
先看一下文献的抠图效果:

感觉很牛的样子,连头发都可以进行抠,然而其实这个算法的计算效率挺低的,到了后面你了解了这个算法,你就会知道速度有多么慢了。
贝叶斯抠图算法
在融合方程中,已知的只有C,而F、B和α 都是未知的。于是可以从条件概率的角度去考虑这个问题,即给定C时,F、B和α的联合概率应为
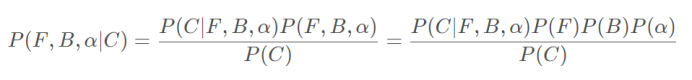
其中第一个等号是根据贝叶斯公式得到的,第二个等号则是考虑F、B和α 是彼此独立的。
上式表明Matting问题可以被转化为已知待计算像素颜色C的情况下,如何估计它的F、B和α 的值以最大化后验概率P ( F , B , α ∣ C )的问题,即MAP问题。
上述等式中的右端项,需要通过采样统计的方式进行估计,而这种估计结果的准确性,很大程度上决定了算法的融合质量。具体来说,算法会采用一个连续滑动的窗口对邻域进行采样,窗口从未知区域和己知区域之间的两条边开始向内逐轮廓推进,计算过程也随之推进。下图左显示了Bayesian Matting方法的采样过程。
这篇paper中将采样窗口定义为一个以待计算点为中心,半径r的圆域。进行采样时,不但要对已知区域进行采样,同时为了在待计算像素周围保持一个连续的α分布,也要对之前计算出的邻域像素点进行采样。需要说明的是,采样窗口必须覆盖己知的前景和背景区域。这是因为用户提供的Trimap不能保证一定是足够精致的,换句话说,未知区域覆盖的像素有很多是纯粹的前景或背景,而非混合像素。如果采样半径内不能保证有己知区域内的像素采样,就有可能造成无法采样到前景或背景色。
算法的核心假设是在前景和背景的交界区域附近,其各自的颜色分布在局部应该是基本一致的。算法的目标是通过上面给出的采样统计结果,在未知区域的每一个待计算点上重建它的前景和背景颜色概率分布,并根据这种分布恢复出它的前景色F,背景色B和α 值。
跟朴素贝叶斯法中处理情况一致,再利用对数似然L ( · ) ,所以有
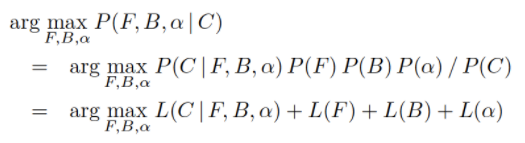
使用对数似然的目的在于等价地把乘法转化成加法。因为P(c)是一个常数,所以在考虑最大化问题时可以将其忽略,上图右展示了一个应用这一规则求解最优F、B和α 的过程。我们就是要求解最优的参数:F、B、alpha值,使得上面的式子的概率最大化。
然而贝爷斯为了保证空间的连贯性,就以每个未知像素的N个邻域点,进行聚类,为了简化起见,paper先假设,前景色只有一类,背景色也只有一类,记住这个只是对于一个像素点的N个领域点而言。至于N的值大小,paper选择200,也就是说每个未知的像素选择最近的200个进行相关的高斯建模。也就是说这200个邻域点,聚类模型前景和背景都是单高斯模型,这样我们就可以求得着200个邻域点属于这个高斯模型的概率了。
泊松图像融合
数学可以说是现代数字图像处理技术的一个重要基石,一些效果显著的同时也非常流行的图像处理技术中大量地借鉴和利用了经典数学理论中的一些著名的成果。尽管这些经典数学理论在其原有场景中的意义与其在图像处理技术中的应用二者之间的关系并没有那么明显!
泊松方程(Poisson Equation)在泊松图像编辑(Poisson Image Editing)以及泊松融合(Poisson Matting)中的应用就是一个典型的例子。
左图 这个人物是西莫恩·德尼·泊松(Siméon-Denis Poisson)是十九世纪法国著名数学家,曾经师从拉普拉斯和拉格朗日两位大师学习数学,数学中许多重要的概念(例如泊松分布、泊松积分、泊松方程 … …) 都以他的名字命名。


泊松编辑
经典物理中,引力场和电场都可以导出泊松方程,这里会设计到很多物理知识,下面重点说一下图像的泊松编辑
引力加速度场中的泊松公式中各物理量的关系如左图所示,下面将这其中的概念平行地转移到数字图像中。理解其中的对应关系是非常有意义的。
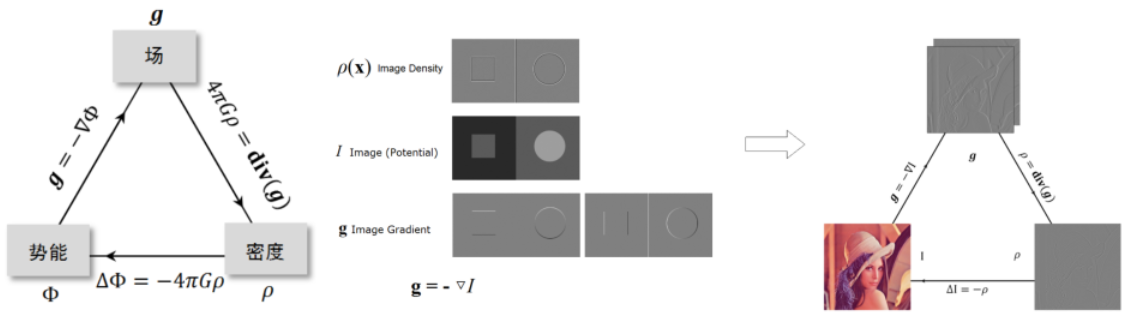
对于一组数字信号而言,它的能量在时域上主要是指它的振幅。而这种振幅对应到图像中,其实就是指各像素的灰度值。所以一幅图像的势能对应的就是原图像自身。对势能求梯度,可以得到相应的场。在图像处理中,可以利用哈密尔顿算子计算原图像的梯度结果,所以这里的场对应的就是图像梯度(注意这里有一个负号)。同理,利用拉普拉斯算子处理原图像,相应得到的就是密度图像。这些概念的对应关系如上图所示。
泊松方程之于图像处理的一个重要应用就是进行图像合成。图像合成是图像处理的一个基本问题,其通过将源图像中一个物体或者一个区域 (抠图) 嵌入到目标图像生成一个新的图像。
Poisson Image Editing
这就引出来2004年Siggraph的经典paper:《Poisson Image Editing》,在图像融合领域,融合效果最牛逼的paper。开始这个算法前,我需要先讲解一个数学问题:
散度计算
现在假设一幅图像为3*3的单通道灰度图像
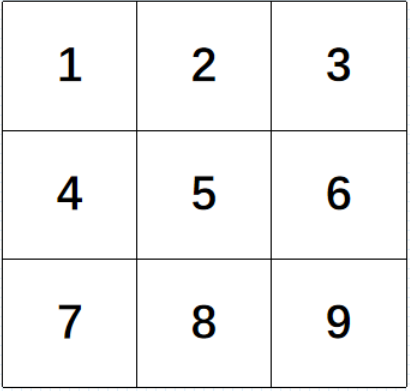
我们假设每一点的像素值为V,V(1)表示像素点1的值,那么我们可以定义像素点5的散度的计算公式为:
div(5)=[V(2)+V(4)+V(6)+V(8)]-4*V(5)
说白了就是通过拉普拉斯卷积核,进行卷积,就可以求解散度了。
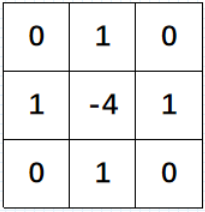
当然正规的过程应该是先求解像素点5的梯度值,然后在对梯度求导,这样就能得到散度,不过得到的结果其实就是上面的计算公式。
泊松重建
OK,现在如果我给定一张图像,那么是不是可以利用拉普拉卷积核,求解每个点的散度
现在反过来,如果我给定每个像素点的散度,我要你求解每个像素点的值,要怎么求取。这便是泊松方程的灵魂了。为了更好的理解重建过程,我现在假设图像的大小是4*4的16个像素点图片,如下:
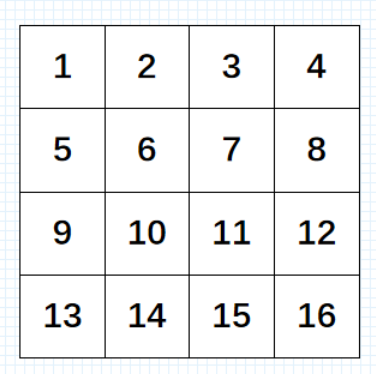
ok,假设我给你像素点6、7、10、11的散度值div(6)、div(7)、div(10)、div(11),那么我们是不是可以列出如下4个方程:
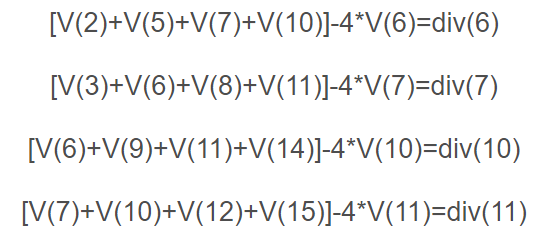
这个时候,如果我们只有四个方程,可是里面有16个像素点,也就是说有16个未知数。因此单单靠上面的4个方程,就想把所有的像素值求解出来是不可能的,这样方程有无数多个解。因此我们需要添加约束方程,这个便是泊松重建方程的约束条件了。假设我们添加边界约束条件,也就是说如果我已经知道了上面那副图像最外围一圈的每个像素点的值u,这样我们就可以得到12个约束方程。即:

上面有12个方程,外加给定的散度4个方程,这样我们有16个方程。这样就可以求解方程组了,这样就能实现通过散度+边界约束条件,实现图像重建。这个便是泊松方程的主要过程
因此泊松融合,说的再简单一点,就是求解方程组:
Ax=b
算法的整个过程在于求解系数稀疏矩阵A、及b。只要A、b求出来了,那么我们就可以求解方程组得到x,而x就是我们得到的融合结果的像素颜色值。
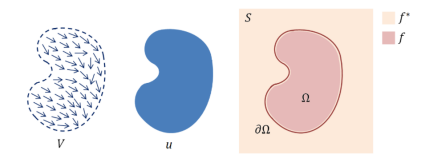
泊松图像编辑的主要思想是,根据原图像的梯度信息以及目标图像的边界信息,利用插值的方法重新构建出和成区域内的图像像素。如图上所示,其中u表示原图像中被合成的部分,V是u的梯度场,S是合并后的图像,Ω是合并后目标图像中被覆盖的区域,∂Ω是其边界。设合并后图像在Ω内的像素值由 f 表示,在外的像素值由 f*表示。
注意到图像合并的要求是使合并后的图像看上去尽量的平滑,没有明显的边界。所以,Ω内的梯度值应当尽可能的小。
最后展示一下这个算法的神器融合效果

实时高分辨率背景抠图
Real-Time High-Resolution Background Matting
CVPR 2021 最佳论文提名
为了使用户更方便地替换背景,研究人员陆续开发了一系列抠图方法。2020年 4 月份,华盛顿大学研究者提出了 background matting 方法,不在绿幕前拍摄也能完美转换视频背景,让整个世界都变成你的绿幕。但是,这项研究无法实现实时运行,只能以低帧率处理低分辨率下(512×512)的背景替换,有很多需要改进的地方。
八个月过去,2021这些研究者推出了 background matting 2.0 版本,并表示这是一种完全自动化、实时运行的高分辨率抠图方法,分别以 30fps 的帧率在 4k(3840×2160)和 60fps 的帧率在 HD(1920×1080)图像上产生非常好结果。
先来看一些效果展示场景:

非常自然流畅的背景替换。
数据集
设计一个对高分辨率人物视频进行实时抠图的神经网络极具挑战性,特别是头发等细粒度细节特别重要的情况。1.0 版本只能以 8fps 的帧率实现 512×512 分辨率下的背景替换。若要在 4K 和 HD 这样的大分辨率图像上训练深度网络,则运行会非常慢,需要的内存也很大。此外,它还需要大量具备高质量前景蒙版(alpha matte)的图像以实现泛化,然而公开可用的数据集也很有限。
为此,他们创建了两个数据集 VideoMatte240K 和 PhotoMatte13K/85,二者均包含高分辨率前景蒙版以及利用色度键软件提取的前景层。研究者首先在这些包含显著多样化人体姿势的较大型前景蒙版数据集上训练网络以学习鲁棒性先验,然后在手动制作的公开可用数据集上继续训练以学习细粒度细节。

模型架构图
此外,为了设计出能够实时处理高分辨率图像的网络,研究者观察发现图像中需要细粒度细化的区域相对很少。所以他们提出了一个 base 网络,用来预测低分辨率下的前景蒙版和前景层,并得到误差预测图(以确定哪些图像区域需要高分辨率细化)。然后 refinement 网络以低分辨率结果和原始图像作为输入,在选定区域生成高分辨率输出。
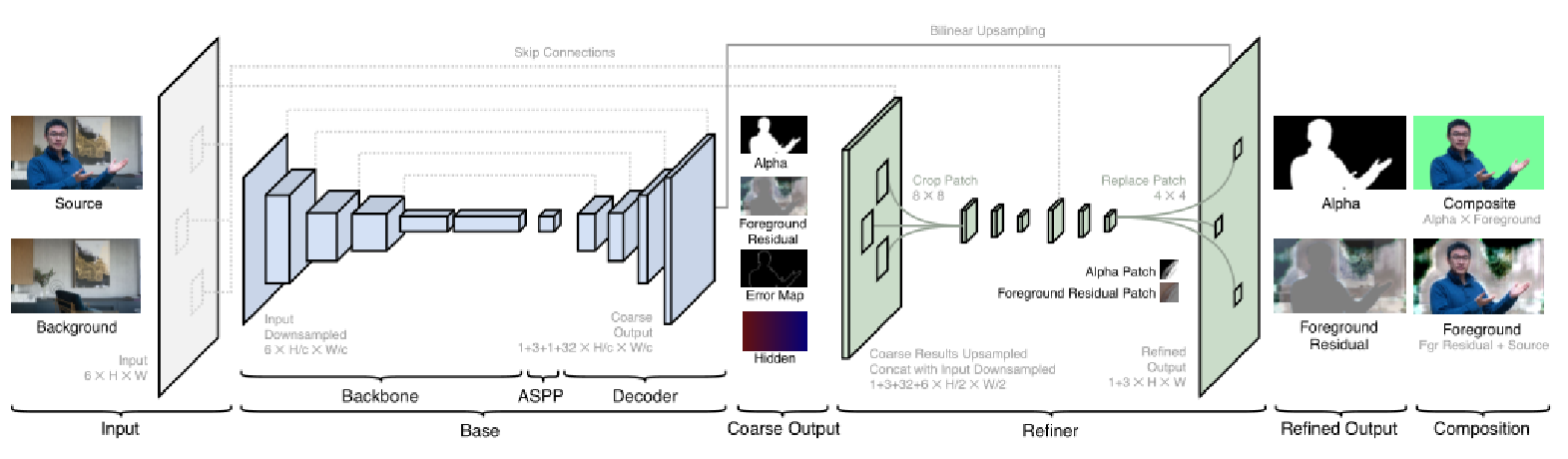
结果表明,Background Matting 2.0 版本在具有挑战性的真实视频和人物图像场景中取得了 SOTA 的实时背景抠图结果。研究者还将公布 VideoMatte240K 和 PhotoMatte85 数据集以及模型实现代码。
实际使用
研究人员将此方法应用到了 Zoom 视频会议和抠图这两种场景中。
在 Zoom 实现中,研究人员构建了拦截摄像头输入的 Zoom 插件,收集一张无人的背景图,然后执行实时视频抠图和合成,实际效果很好。
此外,研究人员对比了该方法和绿幕色度抠图的效果,发现在光照不均匀的环境下,该方法的效果胜过专为绿幕设计的方法,如下图所示:

本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!