机器学习四大门派
本文最后更新于:2022年7月26日 下午
什么是学习?
著名学者赫伯特·西蒙教授(Herbert Simon,1975年图灵奖获得者、1978年诺贝尔经济学奖获得者)曾对“学习”给了一个定义:“如果一个系统,能够通过执行某个过程,就此改进了它的性能,那么这个过程就是学习”。
大牛就是大牛,永远都是那么言简意赅,一针见血。从西蒙教授的观点可以看出,学习的核心目的,就是改善性能。
其实对于人而言,这个定义也是适用的。比如,我们现在正在学习“机器学习”的知识,其本质目的就是为了“提升”自己在机器学习上的认知水平。如果我们仅仅是低层次的重复性学习,而没有达到认知升级的目的,那么即使表面看起来非常勤奋,其实我们也仅仅是个“伪学习者”, 因为我们没有改善性能。
按照这个解释,那句著名的口号“好好学习,天天向上”,就会焕发新的含义:如果没有性 能上的“向上”,即使非常辛苦地“好好”,即使长时间地“天天”,都无法算作“学习”。
什么是机器学习?
赫伯特·西蒙认为Machine learning is the ability to “learn” (i.e., progressively improve performance on a specific task) with data, without being explicitly programmed
英雄所见略同。卡内基梅隆大学的Tom Mitchell教授,在他的名作《机器学习》一书中,也给出了更为具体(其实也很抽象)的定义:对于某类任务(Task,简称T)和某项性能评价准则(Performance,简称P),如果一个计算机程序在T上,以P作为性能的度量,随着很多经验(Experience,简称E)不断自我完善,那么我们称这个计算机程序在从经验E中学习了。
比如说,对于学习围棋的程序AlphaGo,它可以通过和自己下棋获取经验,那么它的任务T就是“参与围棋对弈”;它的性能P就是用“赢得比赛的百分比”来度量。“类似地,学生的任务T就是“上课看书写作业”;它的性能P就是用“期末成绩”来度量”
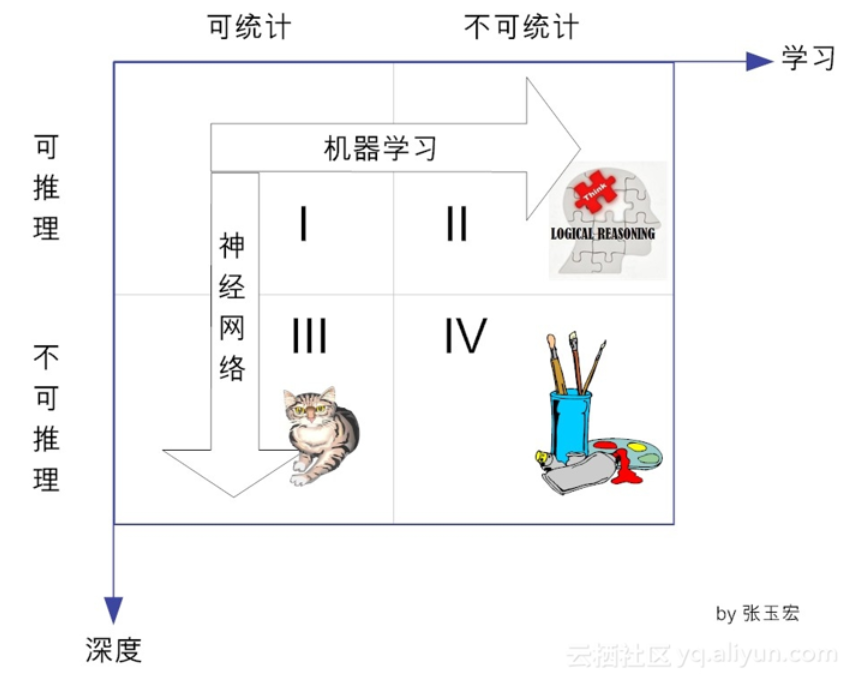
在前面的文章中已提到,一般说来,人类的知识在两个维度上可分成四类,见上图。即从可统计与否上来看,可分为:是可统计的和不可统计的。从能否推理上看,可分为可推理的和不可推理的。
在横向方向上,对于可推理的,我们都可以通过机器学习的方法,最终可以完成这个推理。传统的机器学习方法,就是试图找到可举一反三的方法,向可推理但不可统计的象限进发(象限Ⅱ)。目前看来,这个象限的研究工作(即基于推理的机器学习)陷入了不温不火的境地,能不能峰回路转,还有待时间的检验。
而在纵向上,对于可统计的、但不可推理的(即象限Ⅲ),可通过神经网络这种特定的机器学习方法,以期望达到性能提升的目的。目前,基于深度学习的棋类博弈(阿尔法狗)、计算机视觉(猫狗识别)、自动驾驶等等,其实都是在这个象限做出了了不起的成就。
从图1可知,深度学习属于统计学习的范畴。用李航博士的话来说,统计机器学习的对象,其实就是数据[3]。这是因为,对于计算机系统而言,所有的“经验”都是以数据的形式存在的。作为学习的对象,数据的类型是多样的,可以是各种数字、文字、图像、音频、视频,也可以是它们的各种组合。
统计机器学习,就是从数据出发,提取数据的特征(由谁来提取,是个大是大非问题,下面将给予介绍),抽象出数据的模型,发现数据中的知识,最后又回到数据的分析与预测当中去。
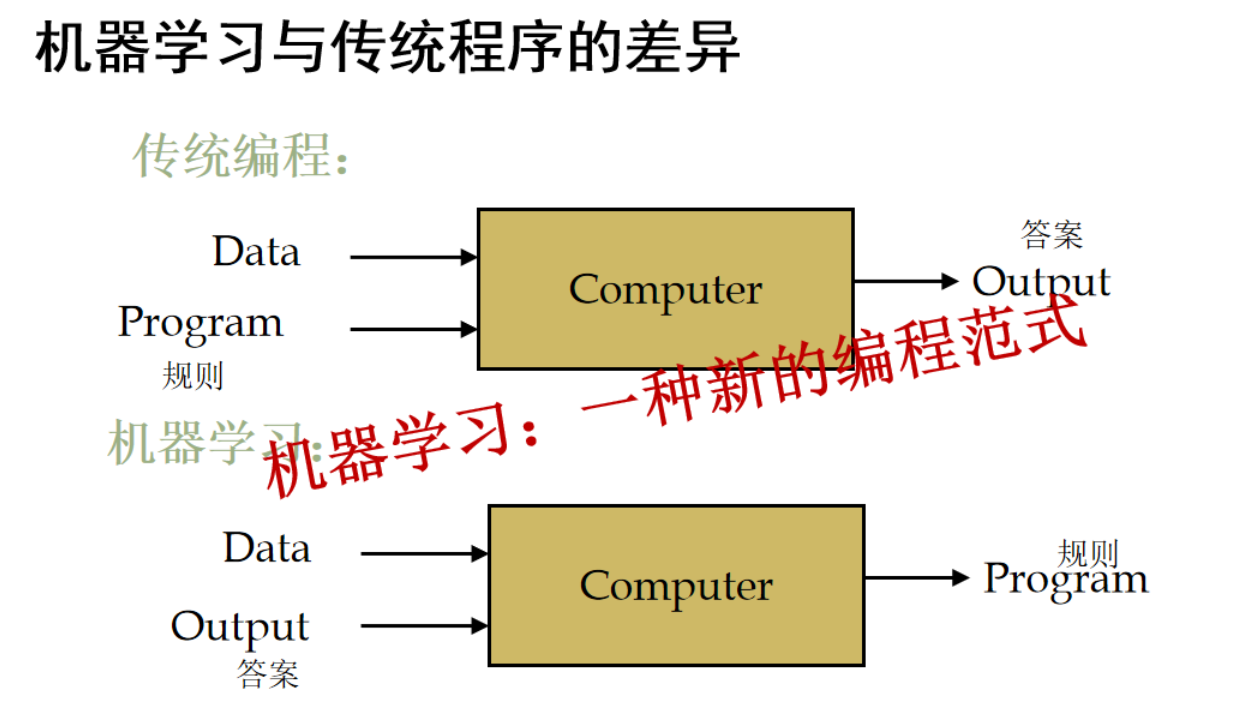
我们今天所有的软件系统,大部分都是人造的长颈鹿,没有学习能力,它所有的能力都是天生给它的,就是人给它的知识,我们都写在了软件代码里面了。沒有學習能力,看再多世界也沒用
机器学习近似于找一个好用的函数

机器学习的核心特征就是–“从数据中学习,获得性能提升“
为什么机器学习不容易
实验:手写体识别
MNIST介绍
MNIST数据集分为训练图像和测试图像。训练图像60000张,测试图像10000张,每一个图片代表0-9中的一个数字,且图片大小均为28*28的矩阵。
train-images-idx3-ubyte.gz: training set images (9912422 bytes) 训练图片
train-labels-idx1-ubyte.gz: training set labels (28881 bytes) 训练标签
t10k-images-idx3-ubyte.gz: test set images (1648877 bytes) 测试图片
t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes) 测试标签
获取MNIST数据的几种方法
方法1
官网下载MNIST数据集的版权在Yann LeCun教授手上,在他的主页下载即可。http://yann.lecun.com/exdb/mnist/下载4个`gz`文件,实际上这也是旧版`TensorFlow`中获取`mnist`的方法。注意,图像数据取值为0到1之间。
方法2
谷歌 https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 下载1个npz文件,实际上这也是新版TensorFlow中获取mnist的方法。注意,图像数据取值为0到255之间。
方法3
通过TensorFlow获取,提前下载好放在这里就可以避免无法下载的问题。
1 | |
方法4
通过Keras获取
1 | |
简单实现
1 | |
机器学习的分类

监督学习
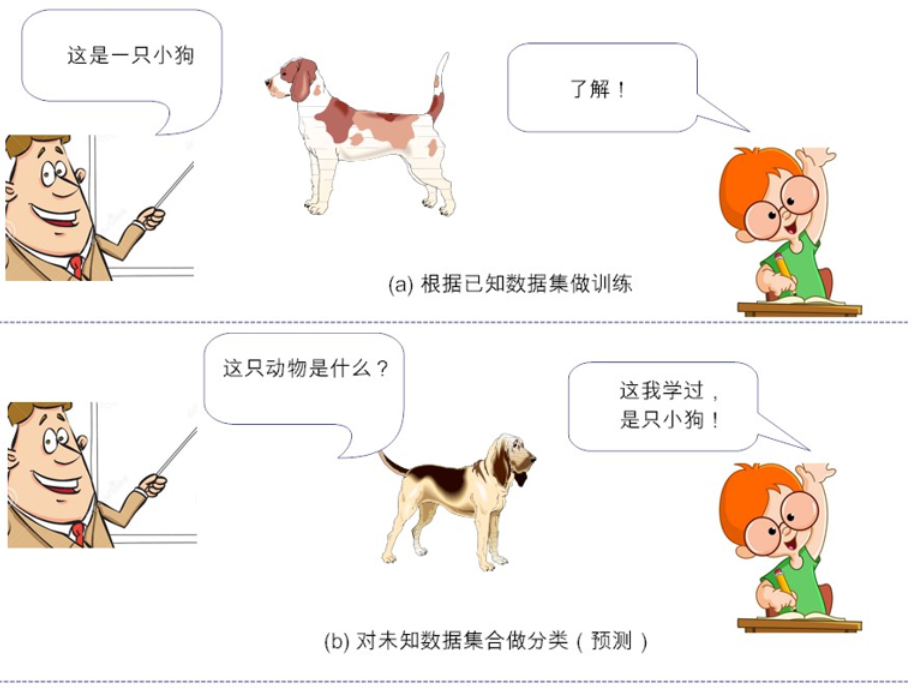
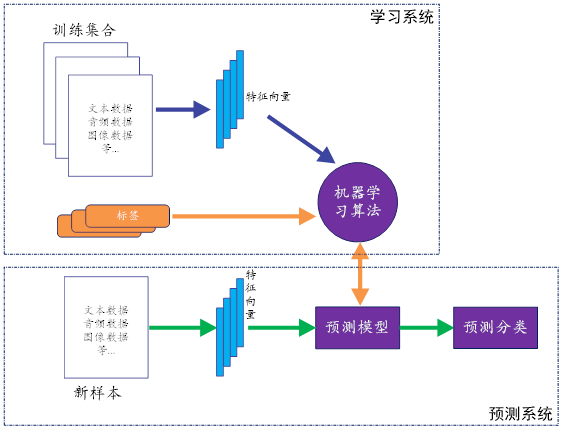
在监督式学习下,输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果。在建立预测模型的时候,监督式学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。
监督学习(Supervised Learning):用数据挖掘大家韩家炜(Jiawei Han)老师的观点来说,监督学习基本上就是“分类(classification)”的代名词。它从有标签的训练数据中学习,然后给定某个新数据,预测它的标签(given data, predict labels)。这里的标签(label),其实就是某个事物的分类。
比如说,小时候父母告诉我们某个动物是猫、是狗或是猪,然后我们的大脑里就会形成或猫或狗或猪的印象,然后面前来了一条“新”小狗,如果你能叫出来“这是一条小狗”,那么恭喜你,你的标签分类成功!但如果你说“这是一头小猪”。这时你的监护人就会纠正你的偏差,“乖,不对呦,这是一头小狗”,这样一来二去的训练,就不断更新你的大脑认知体系,聪明如你,下次再遇到这类新的“猫、狗、猪”等,你就会天才般的给出正确“预测”分类。简单来说,监督学习的工作,就是通过有标签的数据训练,获得一个模型,然后通过构建的模型,给新数据添加上特定的标签。
事实上,整个机器学习的目标,都是使学习得到的模型,能很好地适用于“新样本”,而不是仅仅在训练样本上工作得很好。通过训练得到的模型,适用于新样本的能力,称之为“泛化(generalization)能力”。
分类与回归
诗仙李白在《梦游天姥吟留别》中有一句:
云青青兮欲雨
天气状态,无非是诸如“晴天”、“ 阴天”、雨天或“雪天”等,它们有限的几个离散值,非此即彼,这就是一个典型的分类问题。
《秋浦歌》,里面有句:
白发三千丈,缘愁似个长。
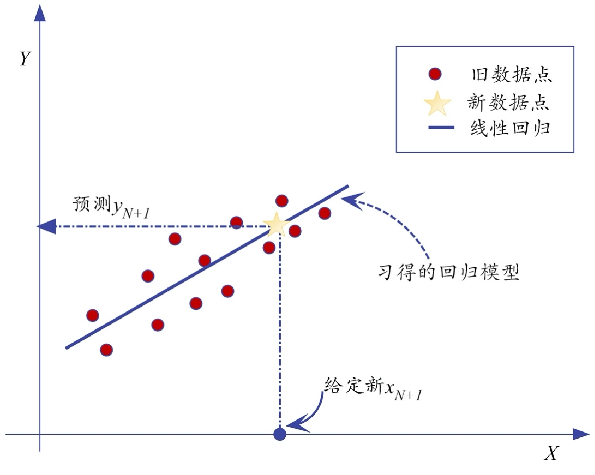
把这类输出状态,看做是连续的。而对输出变量是连续的有监督学习,就属于回归分析问题。
监督学习中的损失函数
衡量实际情况与预测之间的差异——损失函数(loss function),包括但不限于:

无监督学习
在非监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。常见的应用场景包括关联规则的学习以及聚类等。
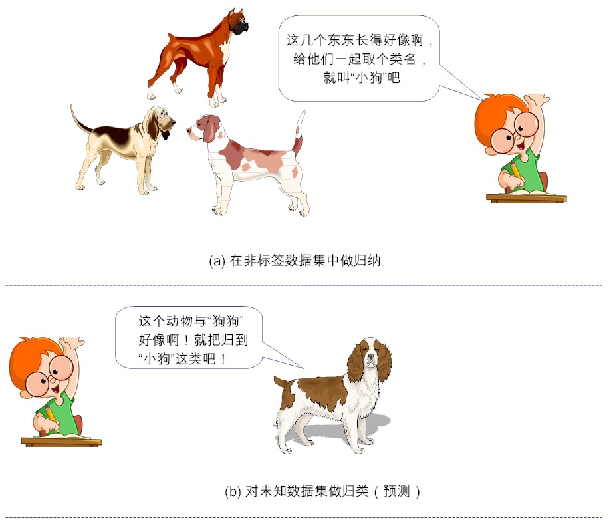
与监督学习相反的是,非监督学习所处的学习环境,都是非标签的数据。韩老师接着说,非监督学习,本质上,就是“聚类(cluster)”的近义词
简单来说,给定数据,从数据中学,能学到什么,就看数据本身具备什么特性了(given data, learn about that data)。我们常说的“物以类聚,人以群分”说得就是“非监督学习”。这里的“类”也好,“群”也罢,事先我们是不知道的。一旦我们归纳出“类”或“群”的特征,如果再要来一个新数据,我们就根据它距离哪个“类”或“群”较近,就“预测”它属于哪个“类”或“群”,从而完成新数据的“分类”或“分群”功能。
k均值聚类
K均值聚类(k-means) 是基于样本集合划分的聚类算法。K均值聚类将样本集合划分为k个子集,构成k个类,将n个样本分到k个类中,每个样本到其所属类的中心距离最小,每个样本仅属于一个类,这就是k均值聚类,同时根据一个样本仅属于一个类,也表示了k均值聚类是一种硬聚类算法。
算法过程:
输入:n个样本的集合
输出:样本集合的聚类
过程:
(1)初始化。随机选择k的样本作为初始聚类的中心。
(2)对样本进行聚类。针对初始化时选择的聚类中心,计算所有样本到每个中心的距离,默认欧式距离,将每个样本聚集到与其最近的中心的类中,构成聚类结果。
(3)计算聚类后的类中心,计算每个类的质心,即每个类中样本的均值,作为新的类中心。
(4)然后重新执行步骤(2)(3),直到聚类结果不再发生改变。
K均值聚类算法的时间复杂度是O(nmk),n表示样本个数,m表示样本维数,k表示类别个数。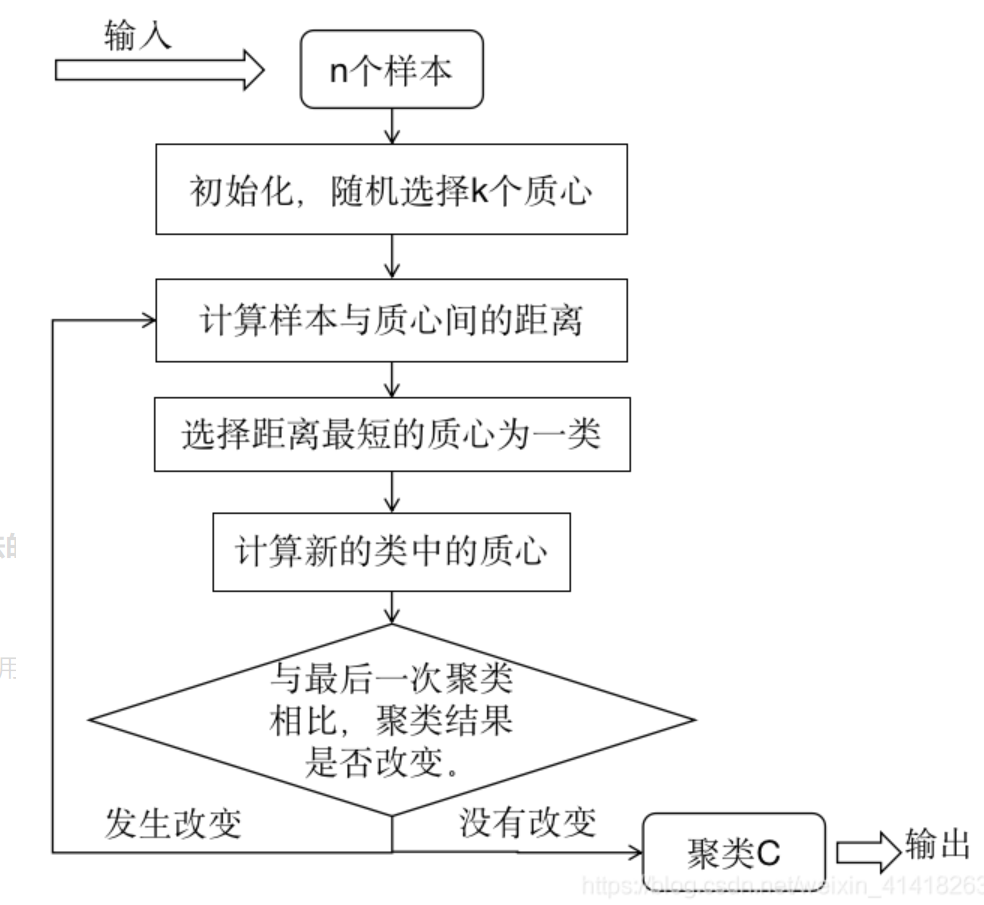
半监督学习
输入数据部分被标识,部分没有被标识
半监督学习就是以“已知之认知(标签化的分类信息)”,扩大“未知之领域(通过聚类思想将未知事物归类为已知事物)”。但这里隐含了一个基本假设——“聚类假设(cluster assumption)”,其核心要义就是:“相似的样本,拥有相似的输出”。
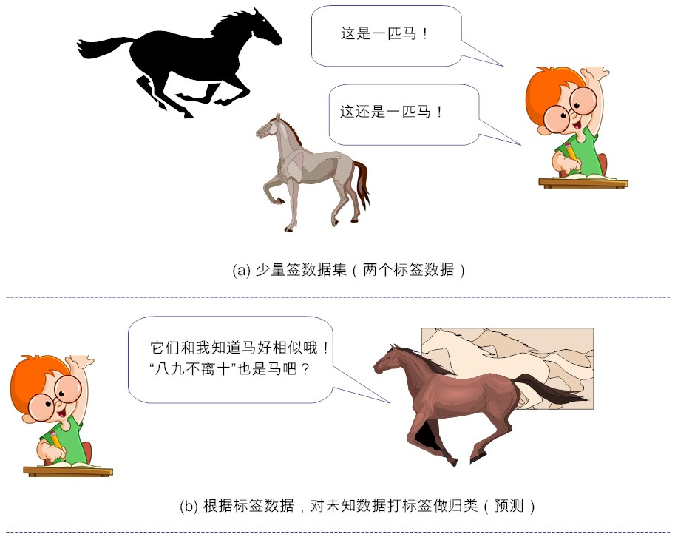
半监督学习(Semi-supervised Learning):这类学习方式,既用到了标签数据,又用到了非标签数据。有句骂人的话,说某个人“有妈生,没妈教”,抛开这句话骂人的含义,其实它说的是“无监督学习”。但我们绝大多数人,不仅“有妈生,有妈教”,还“有小学教,有中学教,有大学教”,“有人教”,这就是说,有人告诉我们事物的对与错(即对事物打了标签),然后我们可据此改善自己的性情,慢慢把自己调教得更有“教养”,这自然就属于“监督学习”。
但总有那么一天我们要长大。而长大的标志之一,就是自立。何谓“自立”?就是远离父母、走出校园后,没有人告诉你对与错,一切都要基于自己早期已获取的知识为基础,从社会中学习,扩大并更新自己的认知体系,然后遇到新事物时,我们能“泰然自若”处理,而非茫然“六神无主”。
形式化的定义比较抽象,下面我们列举一个现实生活中的例子,来辅助说明这个概念。假设我们已经学习到:
(1) 马晓云同学(数据1)是个牛逼的人(标签:牛逼的人)
(2) 马晓腾同学(数据2)是个牛逼的人(标签:牛逼的人)
(3) 假设我们并不知道李晓宏同学(数据3)是谁,也不知道他牛逼不牛逼,但考虑他经常和二马同学共同出没于高规格大会,都经常会被达官贵人接见(也就是说他们虽独立,但同分布),我们很容易根据“物以类聚,人以群分”的思想,把李晓宏同学打上标签:他也是一个很牛逼的人!
这样一来,我们的已知领域(标签数据)就扩大了(由两个扩大到三个!),这也就完成了半监督学习。事实上,半监督学习就是以“已知之认知(标签化的分类信息)”,扩大“未知之领域(通过聚类思想将未知事物归类为已知事物)”。但这里隐含了一个基本假设——“聚类假设(cluster assumption)”,其核心要义就是:“相似的样本,拥有相似的输出”。
强化学习
强化学习会在没有任何标签的情况下,通过先尝试做出一些行为得到一个结果,通过这个结果是对还是错的反馈,调整之前的行为,就这样不断的调整,算法能够学习到在什么样的情况下选择什么样的行为可以得到最好的结果。
如果把机器学习比作一个蛋糕的话,那么强化学习就好比蛋糕上的樱桃,好看但不过是点缀之物,监督学习就好比蛋糕上面的那层糖衣,美味但份额太少。而无(自)监督学习才是蛋糕的本体。
在这之中,杨立昆把无监督学习的重要性提到非常高的地位,而且为了让强化学习更加奏效,也离不开无监督学习的支持。而目前还不成气候的半监督学习,甚至都不入杨立昆的法眼。
三大类机器学习算法
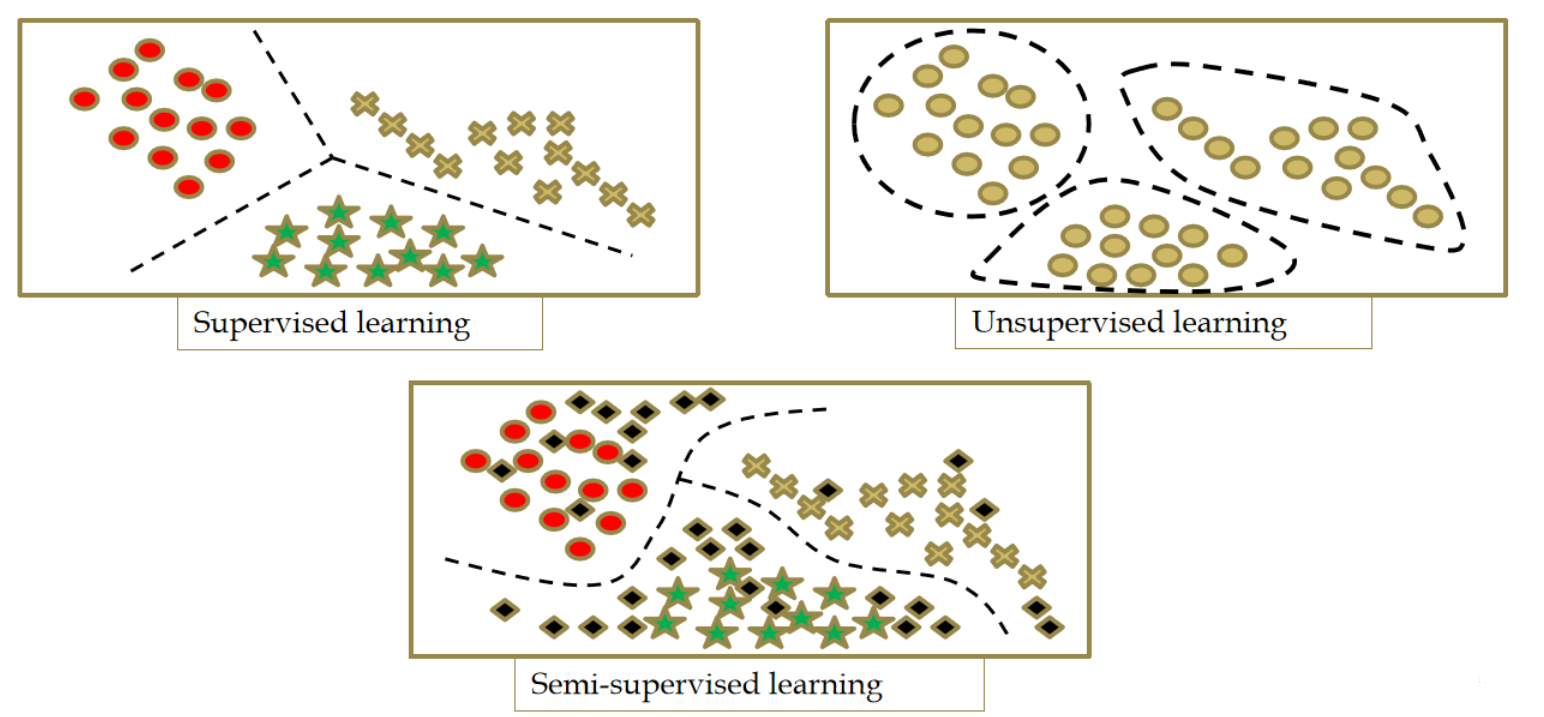
监督学习:有标签,有”教师“指导的学习,分类问题
无监督学习:无标签,利用距离的”亲疏远近“来衡量不同分组,聚类问题
半监督学习:有部分标签,利用聚类扩大标签。不好研究。。。存在瓶颈
事实上,我们对半监督学习的现实需求,是非常强烈的。其原因很简单,就是因为人们能收集到的标签数据非常有限,而手工标记数据需要耗费大量的人力物力成本,但非标签数据却大量存在且触手可及,这个现象在互联网数据中更为凸显,因此,“半监督学习”就显得尤为重要性。
人类的知识,其实都是这样,以“半监督”的滚雪球的模式,越扩越大。“半监督学习”既用到了“监督学习”,也吸纳了“非监督学习”的优点,二者兼顾。
如此一来,“半监督学习”就有点类似于我们中华文化的“中庸之道”了。
参考资料
人工智能极简入门–张玉宏 第二章
https://www.zhihu.com/people/yulaiyuhong
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!