手把手搭建一个简易神经网络
本文最后更新于:2022年7月26日 下午
搭建一个简易神经网络
了解神经网络工作方式的最佳途径莫过于亲自创建一个神经网络,本文将利用感知机解决异或问题。
神经网络(NN)又称人工神经网络(ANN),是机器学习领域中基于生物神经网络概念的学习算法的一个子集。
拥有五年以上经验的德国机器学习专家Andrey Bulezyuk声称:“神经网络正在彻底改变机器学习,因为它们能够在广泛的学科和行业中为抽象对象高效建模。”
神经网络的发展历史
追根溯源,神经网络诞生于人类对于人脑和智能的追问。而这个追问经历了旷远蒙昧的精神至上学说,直到 19 世纪 20 年代。
奥地利医生 Franz Joseph Gall ( 1758-1828 ) 推测人类的精神活动是由脑的功能活动而实现的,这才使人们认识到意识和精神活动具有物质基础,从而使人们对精神活动的认识从唯心主义的错误观点转到了唯物主义的正确轨道上来。
意大利细胞学家 Camillo Golgi ( 1843~1926 )徒手将脑组织切成薄片,用重铬酸钾 - 硝酸银浸染法染色,第一次在显微镜下观察到了神经细胞和神经胶质细胞。这为神经科学的研究提供了最为基本的组织学方法。
西班牙神经组织学家 Santiago Ramón y Cajal ( 1852~1934 )在掌握了 Golgi 染色法后,又进一步改良了 Golgi 染色法,并发明了独创的银染法——还原硝酸银染色法, 此法可显示神经纤维的微细结构 。他发现神经细胞之间没有原生质的联系,因而提出神经细胞是整个神经活动最基本的单位(故称神经元),从而使复杂的神经系统有了进一步研究的切入口。他对于大脑的微观结构研究是开创性的,被许多人认为是现代神经科学之父。他绘图技能出众,他的关于脑细胞的几百个插图至今用于教学。
为此,Santiago Ramón y Cajal 和 Camillo Golgi 两人共享了 1906 年诺贝尔生理学或医学奖。
此后, Cajal 经过大量精细的实验,创立了 “ 神经元学说 ” ,该学说的创立为神经科学的进一步发展开创了新纪元。
对智能机器的探索和计算机的历史一样古老。尽管中文里“电脑”一开始就拥有了“脑”的头衔,但事实上与真正的智能相去甚远。艾伦图灵在他的文章《COMPUTING MACHINERY AND INTELLIGENCE》中提出了几个标准来评估一台机器是否可以被认为是智能的,从而被称为“图灵测试”。
神经元及其连接里也许藏着智能的隐喻,沿着这条路线前进的人被称为连接主义。
1943年,Warren McCulloch 和 Walter Pitts 发表题为《A Logical Calculus of the Ideas Immanent in Nervous Activity》的论文,首次提出神经元的M-P模型。该模型借鉴了已知的神经细胞生物过程原理,是第一个神经元数学模型,是人类历史上第一次对大脑工作原理描述的尝试。
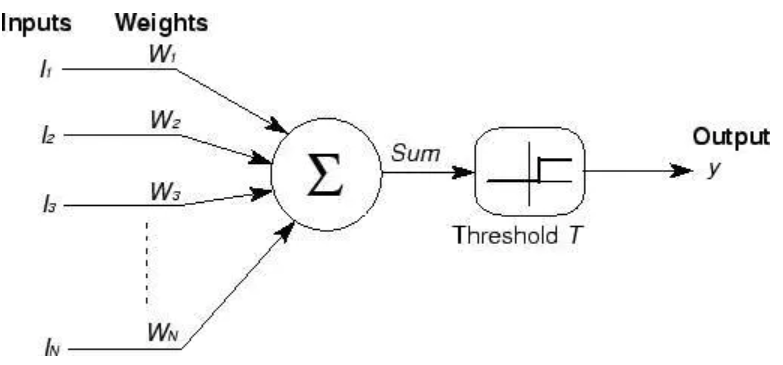
M-P模型的工作原理是神经元的输入信号加权求和,与阈值比较再决定神经元是否输出。这是从原理上证明了人工神经网络可以计算任何算术和逻辑函数。
20世纪40年代末,Donald Olding Hebb在《The Organization of Behavior》中对神经元之间连接强度的变化进行了分析,首次提出来一种调整权值的方法,称为Hebb学习规则。
Hebb学习规则主要假定机体的行为可以由神经元的行为来解释。Hebb受启发于巴普罗夫的条件反射实验,认为如果两个神经元在同一时刻被激发,则它们之间的联系应该被强化。这就是Hebb提出的生物神经元的学习机制,在这种学习中,由对神经元的重复刺激,使得神经元之间的突触强度增加。
Hebb学习规则隶属于无监督学习算法的范畴,其主要思想是根据两个神经元的激发状态来调整期连接关系,以此实现对简单神经活动的模拟。继Hebb学习规则之后,神经元的有监督Delta学习规则被提出,用于解决在输入输出已知的情况下神经元权值的学习问题。
1958年,就职于Cornell航空实验室的Frank Rosenblatt发明了的一种称为感知器(Perceptron)的人工神经网络。它可以被视为一种最简单形式的前馈神经网络,是一种二元线性分类器(激活函数为sign(x))。感知机是人工神经网络的第一个实际应用,标志着神经网络进入了新的发展阶段。
这次成功的应用也引起了许多学者对神经网络的研究兴趣。1960年,斯坦福大学教授Bernard Widrow教授和他的研究生Ted Hoff开发了Adaline(Adaptive Linear Neuron 或 Adaptive Linear Element)和最小均方滤波器(LMS)。Adaline网络和感知机的区别就是将感知机的Step函数换为Linear线性函数。同一时期,Steinbuch等还提出了称为学习矩阵的二进制联想网络。
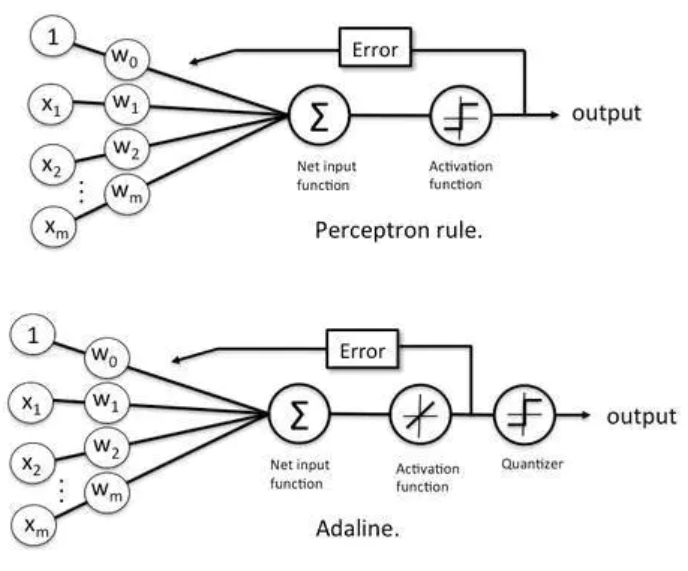
周志华《机器学习》第5章神经网络解释了BP算法实质是LMS算法(Least Mean Square)算法的推广。LMS试图使网络的输出均方差最小化,可用于神经元激活函数可微的感知机学习;将LMS推广到由非线性可微神经元组成的多层前馈神经网络,就得到BP算法,因此BP算法也被称为广义δ规则。
1969年,Marvin Minsky 和 Seymour Papert 发表《Perceptrons: an introduction to computational geometry》一书,从数学的角度证明了单层神经网络具有有限的功能,甚至在面对简单的“异或”逻辑问题时也显得无能为力。此后,神经网络的研究陷入了很长一段时间的低迷期。
1972年,芬兰的KohonenT.教授,提出了自组织神经网络SOM(Self-Organizing feature map)。
1974 年,Paul Werbos在哈佛大学攻读博士学位期间,就在其博士论文中发明了影响深远的著名BP神经网络学习算法。但没有引起重视。
1976年,美国Grossberg教授提出了著名的自适应共振理论ART(Adaptive Resonance Theory),其学习过程具有自组织和自稳定的特征。
1982年,David Parker重新发现了BP神经网络学习算法。
1982年,John Hopfield提出了连续和离散的Hopfield神经网络模型,并采用全互联型神经网络尝试对非多项式复杂度的旅行商问题进行了求解,促进神经网络的研究再次进入了蓬勃发展的时期。
1983年,Hinton, G. E. 和 Sejnowski, T. J.设计了玻尔兹曼机,首次提出了“隐单元”的概念。在全连接的反馈神经网络中,包含了可见层和一个隐层,这就是玻尔兹曼机。
层数的增加可以为神经网络提供更大的灵活性,但参数的训练算法一直是制约多层神经网络发展的一个重要瓶颈。
一个沉睡十年的伟大算法即将被唤醒。
1986年,David E. Rumelhart, Geoffrey E. Hinton 和 Ronald J. Williams发表文章《Learning representations by back-propagating errors》,重新报道这一方法,BP神经网络学习算法才受到重视。BP算法引入了可微分非线性神经元或者sigmod函数神经元,克服了早期神经元的弱点,为多层神经网络的学习训练与实现提供了一种切实可行的解决途径。
1988年,继BP算法之后,David Broomhead 和 David Lowe 将径向基函数引入到神经网络的设计中,形成了径向基神经网络(RBF)。RBF网络是神经网络真正走向实用化的一个重要标志。
1989年,一系列文章对BP神经网络的非线性函数逼近性能进行了分析,并证明对于具有单隐层,传递函数为sigmod的连续型前馈神经网络可以以任意精度逼近任意复杂的连续映射。这样,BP神经网络凭借能够保证对复杂函数连续映射关系的刻画能力(只要引入隐层神经元的个数足够多),打开了Marvin Minsky 和 Seymour Papert 早已关闭的研究大门。
统计学习理论是一种专门研究小样本情况下机器学习规律的理论。Vapnik, V.N.等人从六、七十年代开始致力于此方面研究。到九十年代中期,随着其理论的不断发展和成熟,也由于神经网络等学习方法在理论上缺乏实质性进展,统计学习理论开始受到越来越广泛的重视。同时, 在这一理论基础上发展了一种新的通用学习方法——支持向量机( SVM ),它已初步表现出很多优于已有方法的性能。
此后的近十年时间,神经网络由于其浅层结构,容易过拟合以及参数训练速度慢等原因,曾经火热的神经网络又慢慢的淡出了人们的视线。值得一提的是,1997年,Sepp Hochreiter和Jurgen Schmidhuber首先提出长短期记忆(LSTM)模型。
直到2006年,计算机处理速度和存储能力大大提高,为深度学习的提出铺平了道路。G. E. Hinton 和他的学生 R. R. Salakhutdinov 在《科学》杂志上发表题为《Reducing the Dimensionality of Data with Neural Networks》的文章,掀起了深度学习在学术界和工业界的研究热潮。文章摘要阐述了两个重要观点:一是多隐层的神经网络可以学习到能刻画数据本质属性的特征,对数据可视化和分类等任务有很大帮助;二是可以借助于无监督的“逐层初始化”策略来有效克服深层神经网络在训练上存在的难度。
这篇文章是一个分水岭,拉开了深度学习大幕,标志着深度学习的诞生。从此,历史这样写就:从感知机提出,到BP算法应用以及2006年以前的历史被称为浅层学习,以后的历史被称为深度学习。
总结起来,典型的浅层学习模型包括:传统隐马尔可夫模型(HMM)、条件随机场(CRFs)、最大熵模型(MaxEnt)、boosting、支持向量机(SVM)、核回归及仅含单隐层的多层感知器(MLP)等。
同年,G. E. Hinton 又提出了深度信念网络(Deep BeliefNetwork, DBN) 。深度信念网络基于受限玻尔兹曼机构建。
限制玻尔兹曼机(RBM)是一种玻尔兹曼机的变体,但限定模型必须为二分图。模型中包含对应输入参数的输入(可见)单元和对应训练结果的隐单元,图中的每条边必须连接一个可见单元和一个隐单元。与此相对,“无限制”玻尔兹曼机(BM)包含隐单元间的边,使之成为递归神经网络。BM 由Geoffrey Hinton 和 Terry Sejnowski 在1985年发明,1986年Paul Smolensky 命名了RBM,但直到Geoffrey Hinton及其合作者在2006年左右发明快速学习算法后,受限玻兹曼机才变得知名。
自动编码器早在1986年就被Rumelhart等人提出(也有资料说第一个自动感应器是福岛神经认知机),2006年之后,G. E. Hinton 等人又对自动编码器进行改造,出现了深度自编码器,稀疏自编码器等。2008年,Pascal Vincent和 Yoshua Bengio 等人在《Extracting and composing robust features with denoising autoencoders》中提出了去噪自编码器,2010年又提出来层叠去噪自编码器。2011年,Richard Socher等人也提出了递归自编码器 (RAE)。
目前,卷积神经网络作为深度学习的一种,已经成为当前图像理解领域研究的热点。早在1989年,Yann Le Cun在贝尔实验室就开始使用卷积神经网络识别手写数字;1998年,Yann Le Cun提出了用于字符识别的卷积神经网络LeNet5,并在小规模手写数字识别中取得了较好的结果。基于这些工作,Yann Le Cun也被称为卷积网络之父。2012年,Alex Krizhevsky等使用采用卷积神经网络的AlexNet在ImageNet竞赛图像分类任务中取得了最好成绩,是卷积神经网络在图像分类中的巨大成功。随后Alex Krizhevsky.,Ilya Sutskever.和 Geoffrey Hinton.发表了文章《ImageNet Classification with Deep Convolutional Neural Networks》 。
2013年,Graves 证明,结合了长短时记忆(long short terms memory, LSTM) 的递归神经网络(recurrent neural network, RNN)比传统的递归神经网络在语音处理方面更有效。2014年至今, 深度学习在很多领域都取得了突破性进展,发展出了包括注意力(attention),RNN–CNN, 以及深度残差网络等多种模型。
最后,给出一个神经网络发展历史的回顾总结:
人工神经网络基本上由以下组件组成:
- 输入层:接收并传递数据
- 隐藏层(隐含层)
- 输出层
- 各层之间的权重
- 每个隐藏层都有一个激活函数。
我们搭建一个包含隐含层的神经网络来解决”异或“问题,所谓”异或“,就是输入两个值不同,输出为1,输入两个值相同,输出为0.
excel版本实现
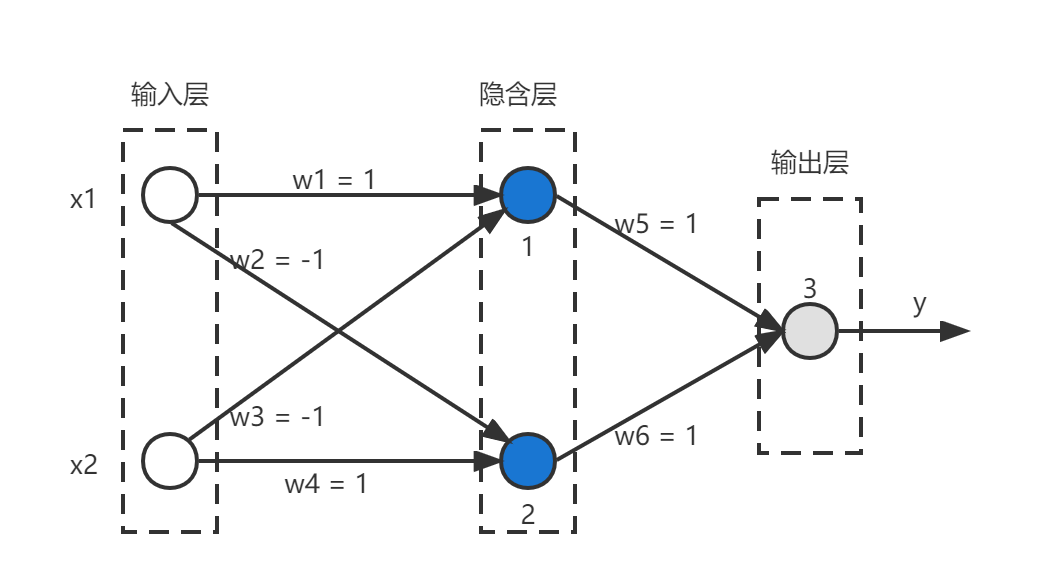
如上图所示的神经元(即实心圆)中,其激活函数是阶跃函数(sgn函数,x>=0时f(x)=1,else f(x) = 0 ),假设各个神经元的阈值θ均为0.5
当x1和x2相同(假设均为1时),对于隐含层的神经元1来说,输出可以表述为
f1 = sgn(x1*w1 + x2*w3 - θ) = sgn(1*1 + 1*(-1) - 0.5 ) = sgn(-0.5) = 0
激活函数的作用体现在Excel单元格E2中输入的公式上
1 | |
类似地,对于隐含层的神经元2有
f2 = sgn(x1*w2 + x2*w4 - θ) = sgn(1*1 + 1*(-1) - 0.5 ) = sgn(-0.5) = 0
激活函数的作用体现在Excel单元格E4中输入的公式上
1 | |
接着对于输出层的输出神经元y而言,隐含层的f1和f2都是它的输入,于是有:
y = f3 = sgn(f1*w5 + f2*w6 - θ) = sgn(0*1 + 0*1 - 0.5) = sgn(-0.5) = 0
对应体现在Excel单元格H3中输入的公式上
1 | |
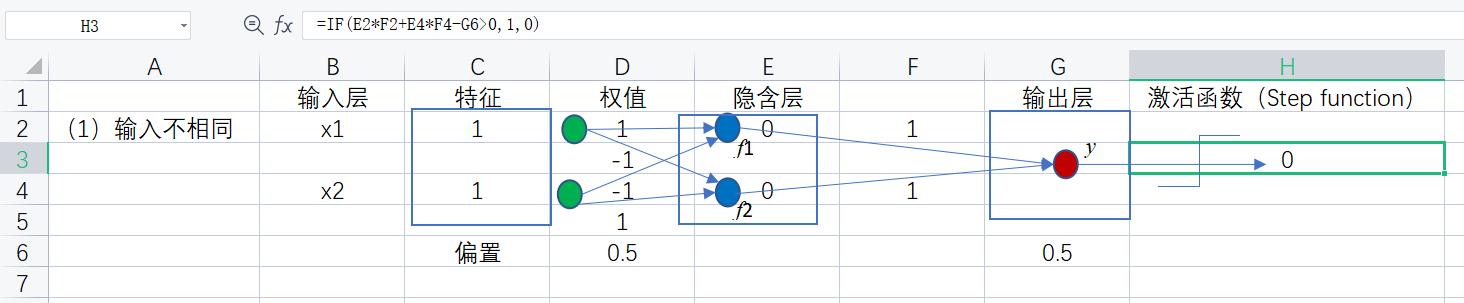
如图我们可以看到其结果为0,满足异或的功能,神经网络搭建完成,剩下的就是更改输入即可,无需更改任何公式,一切都是自动更新计算的,读者可以自行尝试,我们可以感性认识到,网络层次越深,神经网络的表征能力越强。
或许你会疑惑,神经网络的权值和阈值时怎么知道的,在这个案例中我们直接给了出来,而实际上,他们是需要神经网络自己反复“试错”学习而来的,而且能完成“异或”功能的网络权重也不唯一。
python版本实现
MLPClassifier是一个监督学习算法,下图是只有1个隐藏层的MLP模型 ,左侧是输入层,右侧是输出层。
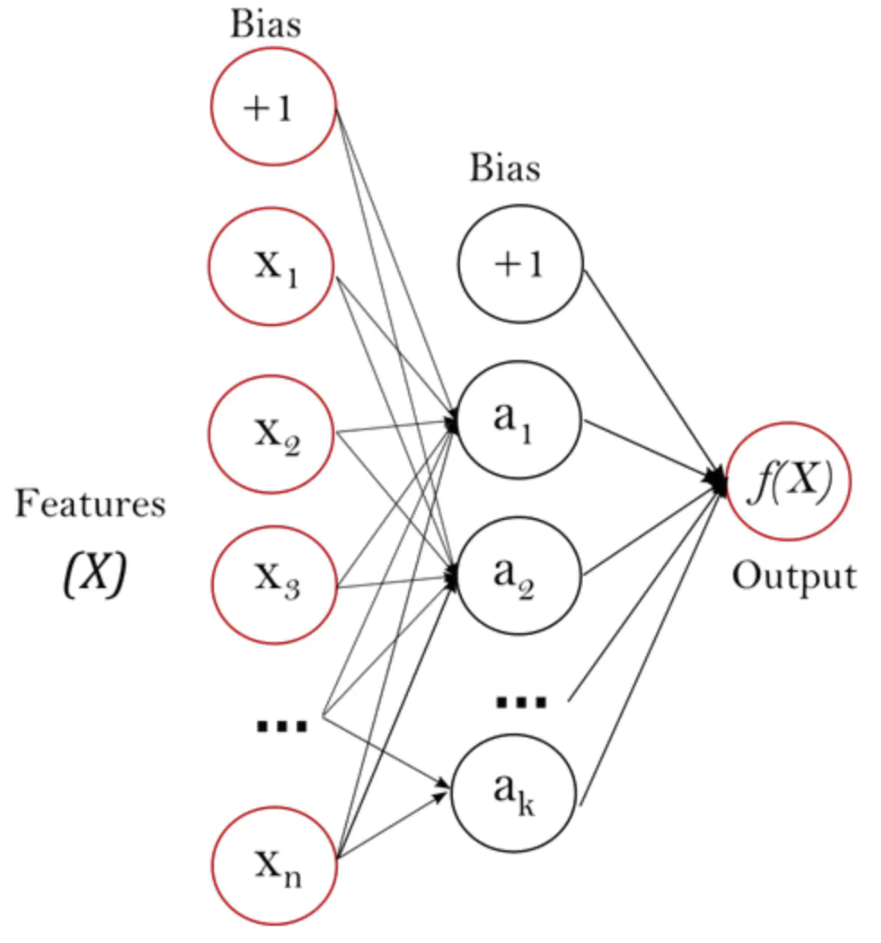
上图的整体结构可以简单的理解为下图所示:
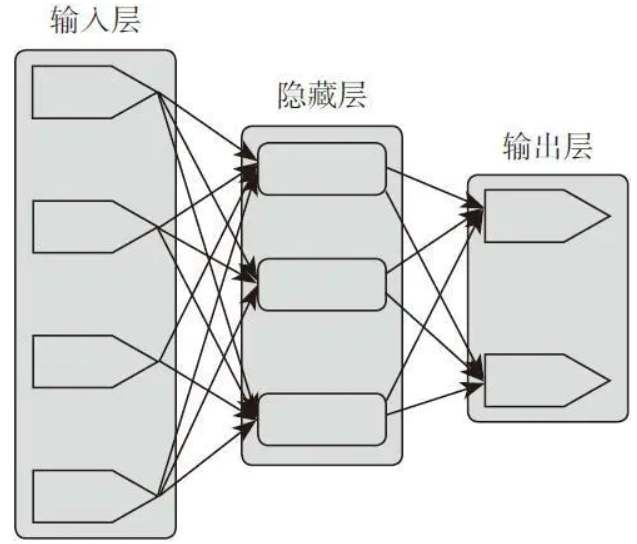
MLP又名多层感知机,也叫人工神经网络(ANN,Artificial Neural Network),除了输入输出层,它中间可以有多个隐藏层,如果没有隐藏层即可解决线性可划分的数据问题。最简单的MLP模型只包含一个隐藏层,即三层的结构,如上图。
从上图可以看到,多层感知机的层与层之间是全连接的(全连接的意思就是:上一层的任何一个神经元与下一层的所有神经元都有连接)。多层感知机最底层是输入层,中间是隐藏层,最后是输出层。
输入层没什么好说,你输入什么就是什么,比如输入是一个n维向量,就有n个神经元。
隐藏层的神经元怎么得来?首先它与输入层是全连接的,假设输入层用向量X表示,则隐藏层的输出就是
f(W1X+b1),W1是权重(也叫连接系数),b1是偏置,函数f 可以是常用的激活函数如 sigmoid函数或者tanh函数
最后就是输出层,输出层与隐藏层是什么关系?其实隐藏层到输出层可以看成是一个多类别的逻辑回归,也即softmax回归,所以输出层的输出就是softmax(W2X1+b2),X1表示隐藏层的输出f(W1X+b1)。
因此,MLP所有的参数就是各个层之间的连接权重以及偏置,包括W1、b1、W2、b2。对于一个具体的问题,怎么确定这些参数?求解最佳的参数是一个最优化问题,解决最优化问题,最简单的就是梯度下降法了(sgd):首先随机初始化所有参数,然后迭代地训练,不断地计算梯度和更新参数,直到满足某个条件为止(比如误差足够小、迭代次数足够多时)。这个过程涉及到代价函数、规则化(Regularization)、学习速率(learning rate)、梯度计算等。
1 | |
输出结果:
1 | |
MLPClassifier参数说明:
activation:激活函数
max_iter:int 最大迭代次数默认200
例如hidden_layer_sizes=(50, 50),表示有两层隐藏层,第一层隐藏层有50个神经元,第二层也有50个神经元。
solver用来优化权重 lbfgs:quasi-Newton方法的优化器
练习题
编程实现:通过如下数据集,预测输入[1, 1, 0]的输出
| 样本编号 | 输入 | 输出 | 样本编号 | 输入 | 输出 |
|---|---|---|---|---|---|
| 样本1 | 0 0 1 | 0 | 样本5 | 1 0 0 | 0 |
| 样本2 | 0 1 1 | 1 | 样本6 | 1 1 1 | 0 |
| 样本3 | 1 0 1 | 1 | 样本7 | 0 0 0 | 0 |
| 样本4 | 0 1 0 | 1 | 新样本 | 1 1 0 | ? |
代码实现:
1 | |
参考资料
手把手教你用Python创建简单的神经网络(附代码) | 机器之心 (jiqizhixin.com)
人工智能极简入门-张玉宏著(12 封私信 / 80 条消息) 玉来愈宏 - 知乎 (zhihu.com)
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!