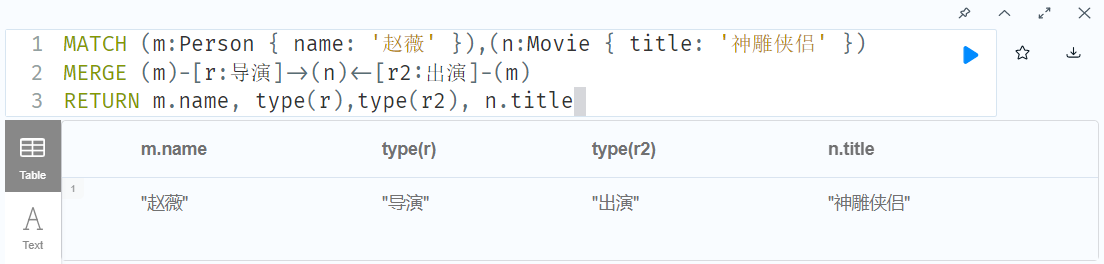
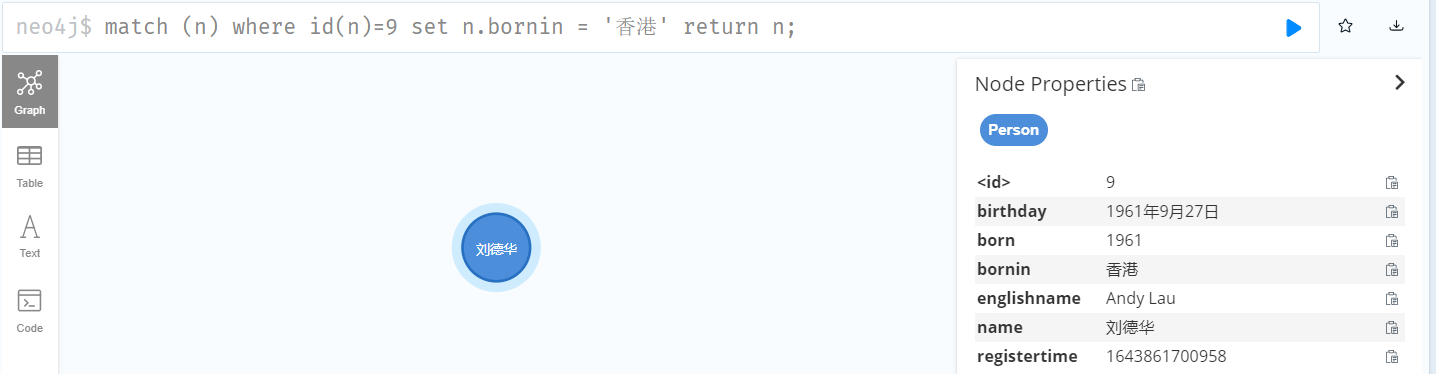
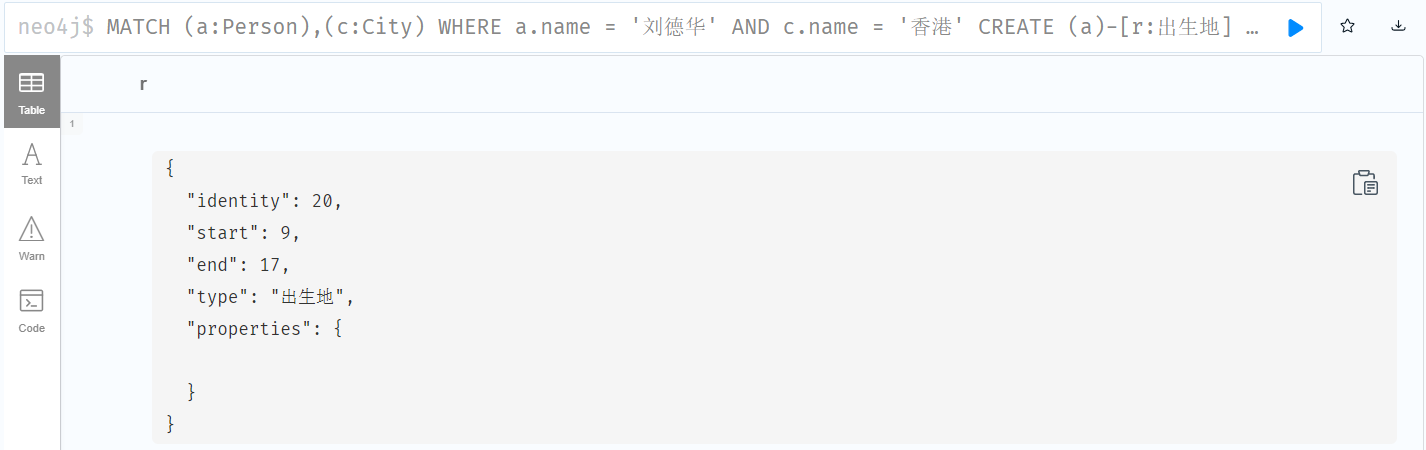
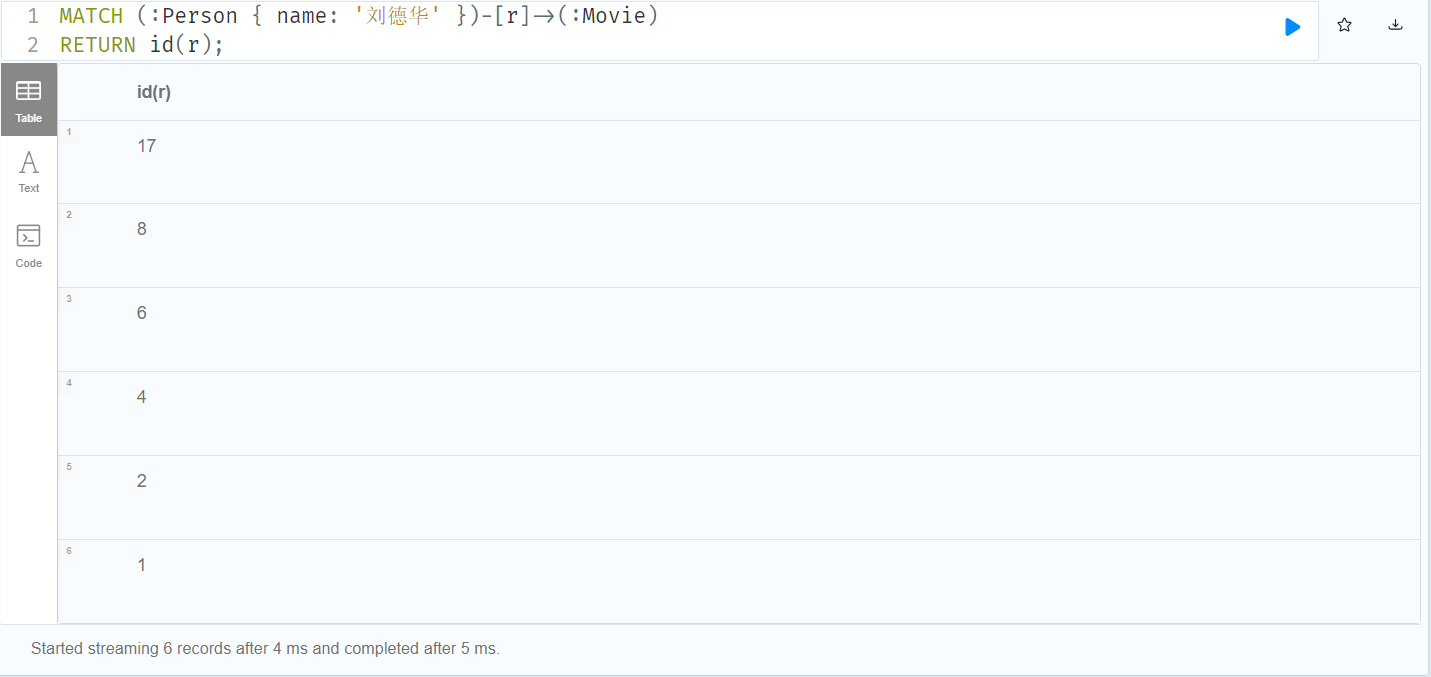
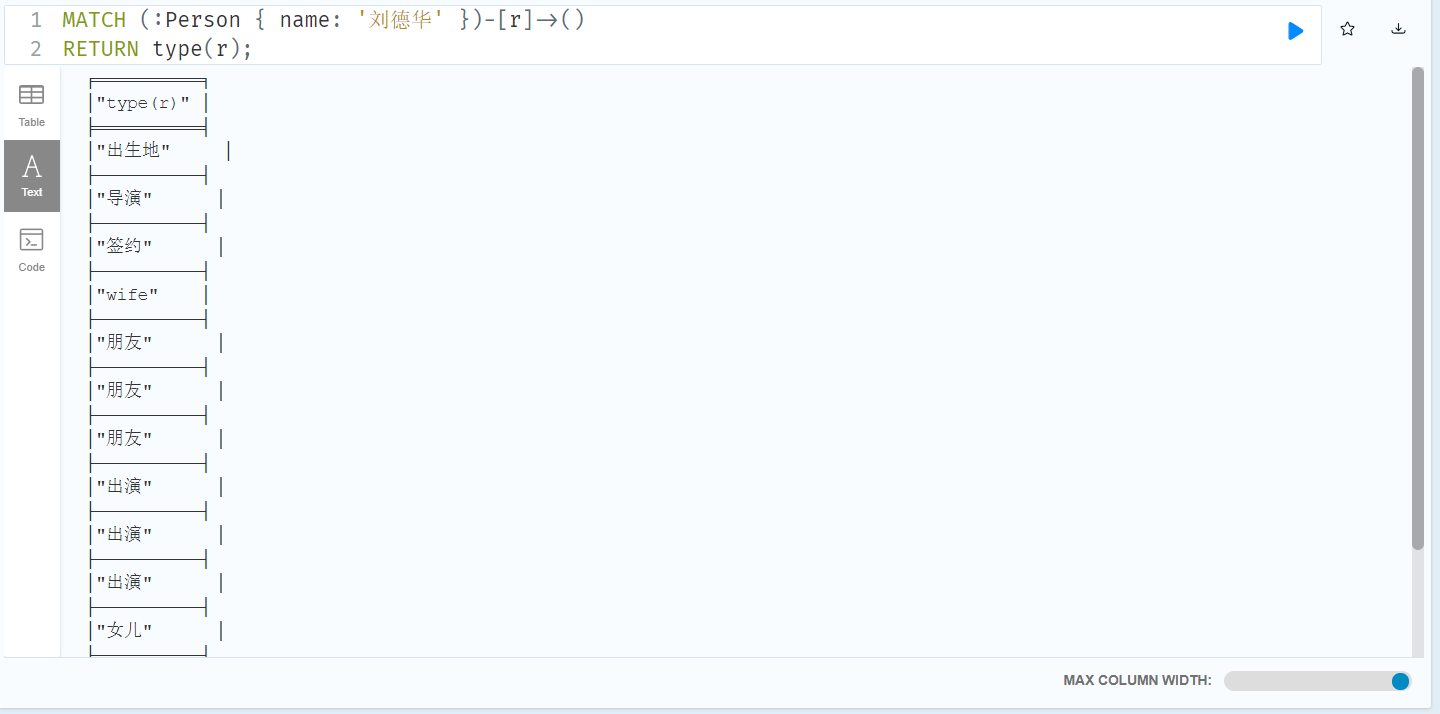
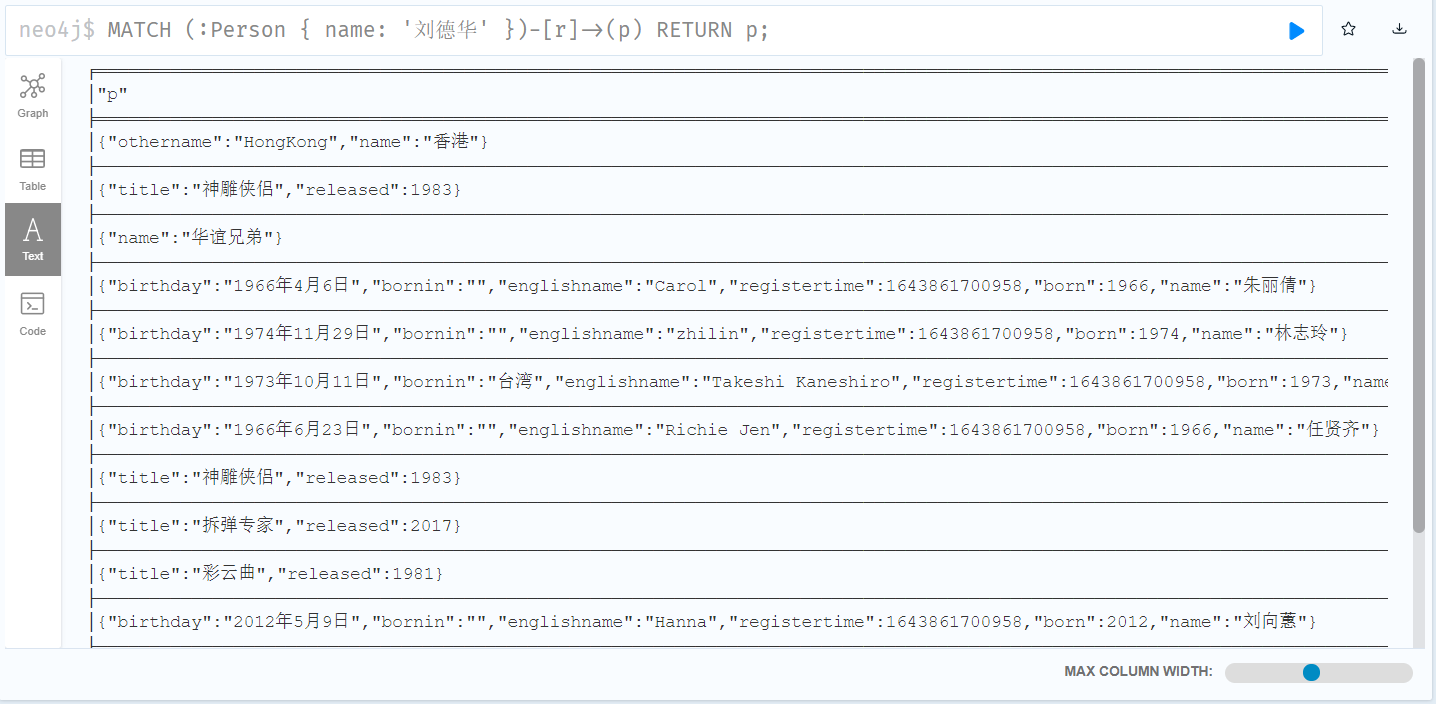
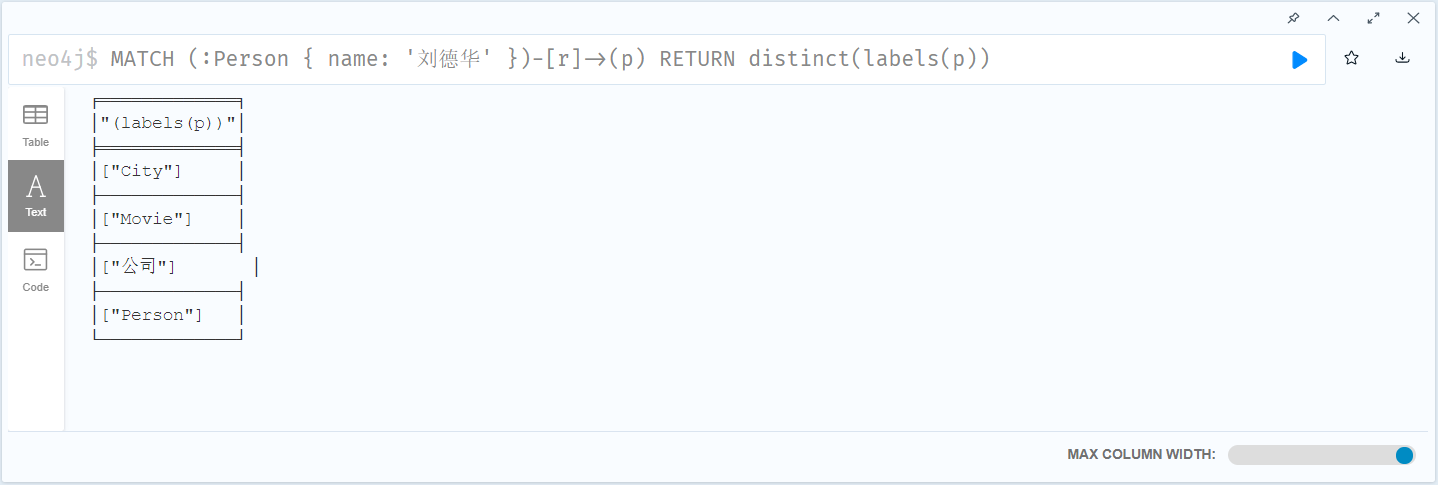
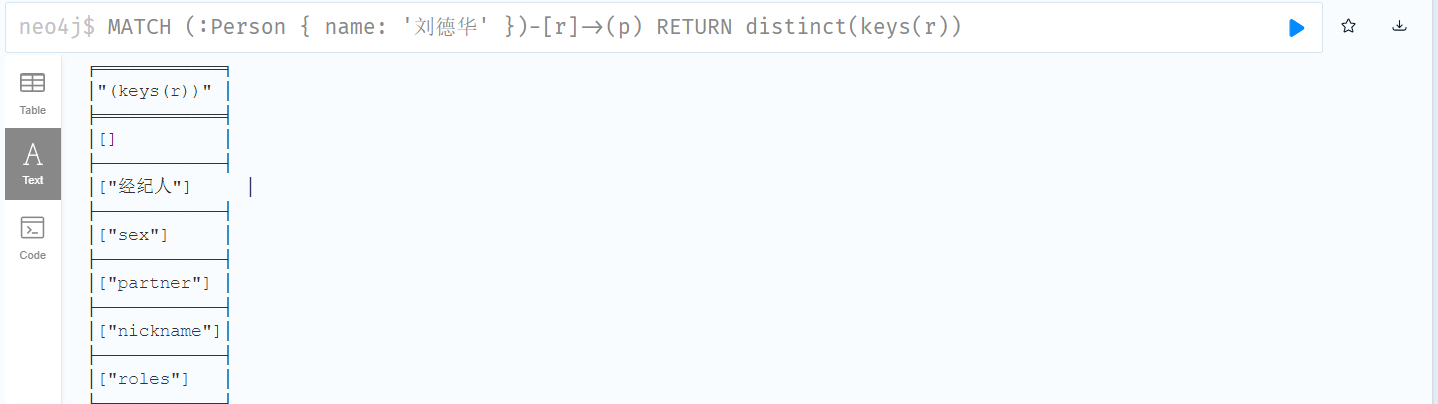
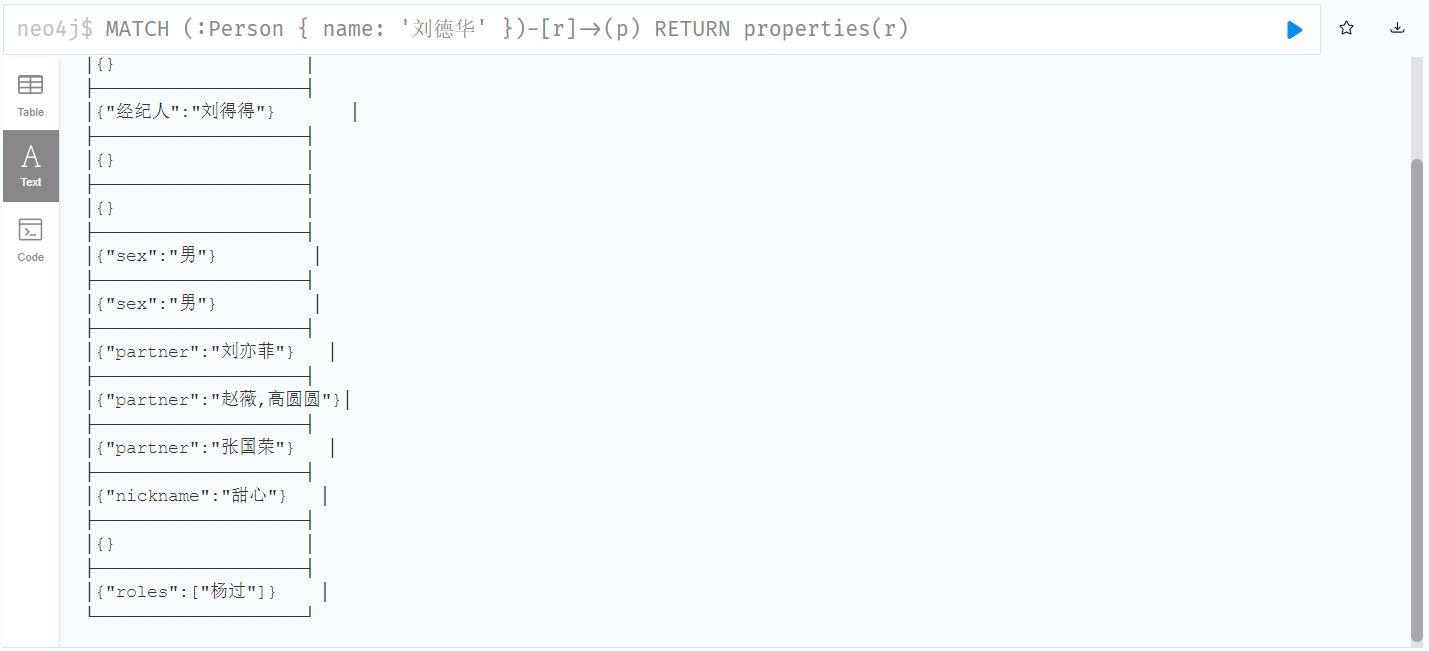
MERGE (m:Person { name: '杰森·斯坦森' }) ON CREATE SET m.registertime = timestamp() RETURN m.name, m.registertime
在merge子句中指定on match子句
如果节点已经存在于数据库中,那么执行on match子句,修改节点的属性;节点属性不存在则新增
1 2 3
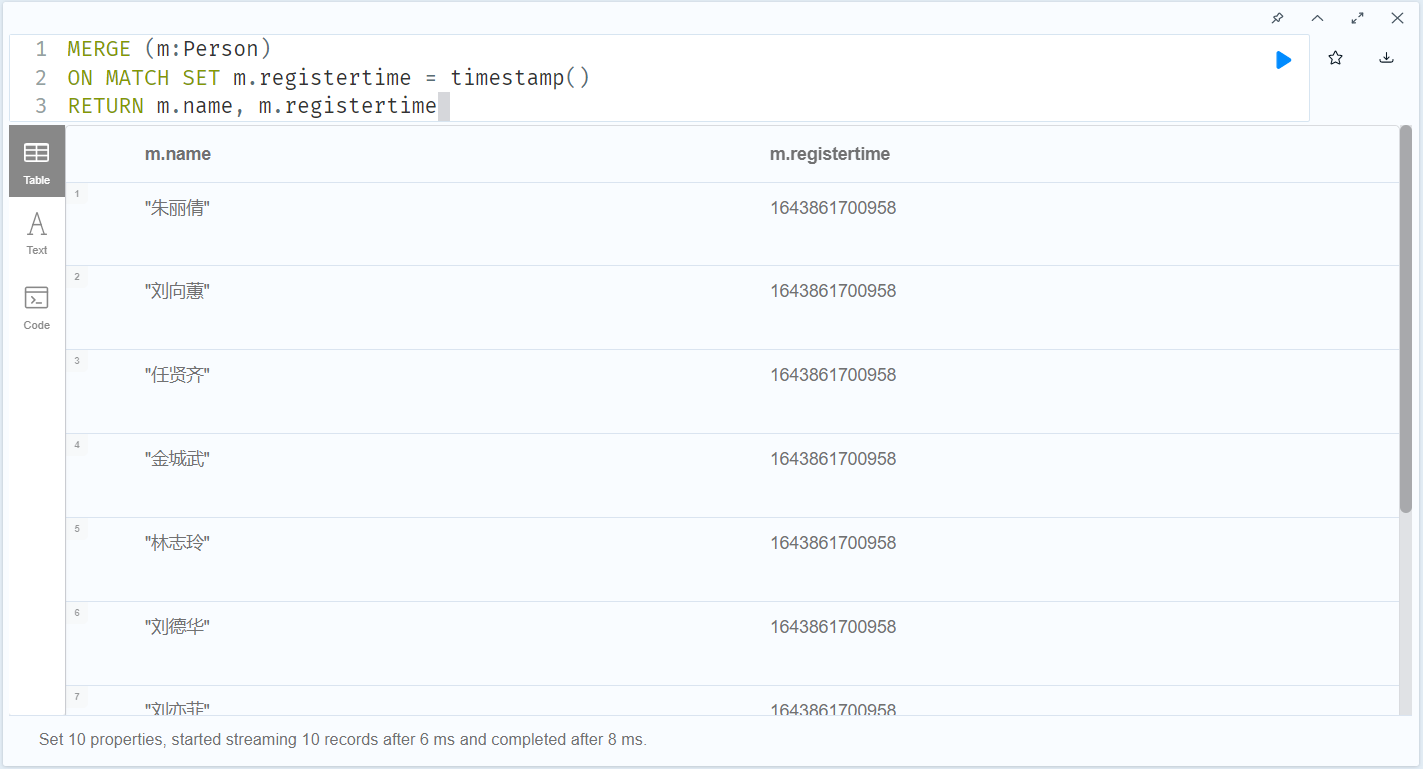
MERGE (m:Person) ON MATCH SET m.registertime = timestamp() RETURN m.name, m.registertime
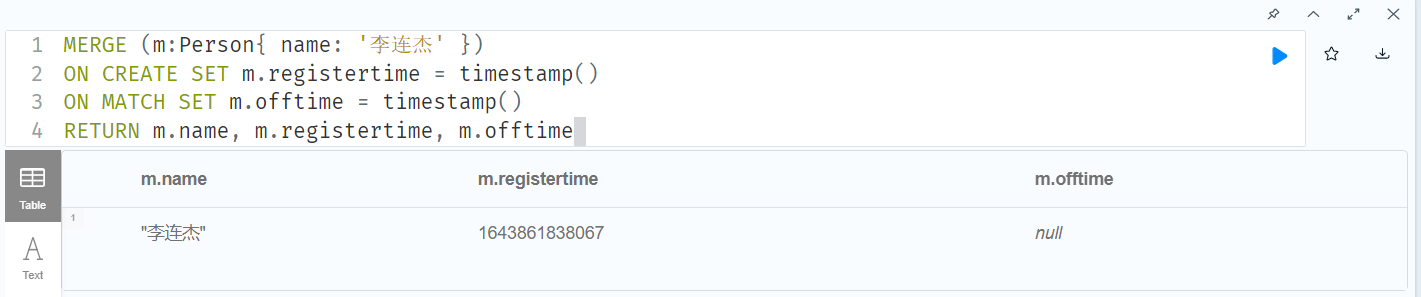
在merge子句中同时指定on create 和 on match子句(没有对应属性则不修改,不会新增属性)
1 2 3 4
MERGE (m:Person{ name: '李连杰' }) ON CREATE SET m.registertime = timestamp() ON MATCH SET m.offtime = timestamp() RETURN m.name, m.registertime, m.offtime
USING PERIODIC COMMIT 500 LOAD CSV FROM "file:///D:\\test.csv" AS line MERGE (:`顶顶顶` {name:line[0]}) LOAD CSV WITH HEADERS FROM "file:///C:\\Program Files\\Java\\neo4j-community-3.4.7\\import\\stock_concept.csv" AS line return line.n
1 2 3
USING PERIODIC COMMIT 10 LOAD CSV FROM "file:///node.csv" AS line create (a:Node{name:line[0]})
1 2 3
USING PERIODIC COMMIT LOAD CSV FROM 'file:///concept.csv' AS row CREATE (n:概念{name:row[1],uuid:row[0]})
csv 不带header方式
1 2 3 4 5
USING PERIODIC COMMIT LOAD CSV FROM "file:///executive_stock.csv" AS row MATCH (n:高管 {uuid: row[0]}) MATCH (m:企业 {uuid: row[1]}) MERGE (n)-[:RE{name:row[2]}]->(m)
带header方式
1 2 3
USING PERIODIC COMMIT LOAD CSV WITH HEADERS FROM 'file:///industry.csv' AS row CREATE (:行业{name:row.name,uuid:row.uuid})
MATCH (n:`zhctwh`)-[r:RE]->(m:`zhctwh`) WITH collect(DISTINCT n) AS cn, collect(DISTINCT m) AS cm, collect(r) AS rships CALL apoc.export.csv.data(cn+cm, rships, "ctwh-re.csv", {}) YIELD file, source, format, nodes, relationships, properties, time, rows, batchSize, batches, done, data RETURN file, source, format, nodes, relationships, properties, time, rows, batchSize, batches, done, data
注意:导出文件如果如上面语句没写路径,默认在安装目录的根目录下,bin所在的同级目录
关于neo4j查询多深度关系节点
1.使用with关键字
查询三层级关系节点如下:with可以将前面查询结果作为后面查询条件
1
match (na:company)-[re]->(nb:company) where na.id = '11' WITH na,re,nb match (nb:company)-[re2]->(nc:company) return na,re,nb,re2,nc
2.直接拼接关系节点查询
1
match (na:company{id:'12399145'})-[re]->(nb:company)-[re2]->(nc:company) return na,re,nb,re2,nc
3.为了方便,可以将查询结果赋给变量,然后返回
1
match data=(na:company{id:'12'})-[re]->(nb:company)-[re2]->(nc:company) return data
4.使用深度运算符
当实现多深度关系节点查询时,显然使用以上方式比较繁琐。
可变数量的关系->节点可以使用**-[:TYPE*minHops..maxHops]->**。
查询:
如果在1到3的关系中存在路径,将返回开始点和结束点。
1
match data=(na:company{id:'12399145'})-[*1..3]->(nb:company) return data
MATCH (n:国家电网) WITH n.name AS name, COLLECT(n) AS nodelist, COUNT(*) AS count WHERE count > 1 CALL apoc.refactor.mergeNodes(nodelist) YIELD node RETURN node
查询某个节点有关系的3级及以内的路径
1 2 3
MATCH (n:`贵州`) WHERE n.name='交通事件' CALL apoc.path.spanningTree(n, {maxLevel:3}) YIELD path RETURN path;
复制领域
1 2 3 4 5
match(n:菊花) MERGE (:大萨达{name:n.name}) match(n:菊花)-[r]->(q:菊花) with n, r, q match (o:大萨达{name:n.name}), (m:大萨达{name:q.name}) MERGE (o)-[:RE{name:r.name}]->(m)
keys函数
查询某个属性大于0 的节点
1
match(n) where any(x in keys(n) where n[x] > 0) return n
查询所有属性大于0的节点
1
match(n) where all(x.uuid in keys(n) where n[x.uuid] > 0) return n
x在any中是一个变量,并不是属性
uuid大于0
1
match(n) where any(uuid in keys(n) where n[uuid] > 0) return n
所有uuid都大于0
1
match(n) where all(uuid in keys(n) where n[uuid] > 0) return n
1
match(n) where any(querytype in keys(n) where n[querytype] = 0) return n
修改密码
进入neo4j提供的可视化界面broswer
输入: :server change-password
键入原密码及新密码,即可修改
设置权重
1 2 3 4
match (n:`测试权重`{name:'项目名称'}),(m:`测试权重`{name:'设计速度'}) MATCH p=(n)-[*]-(m) with p,reduce(s=0,r in rels(p)|s+toInt(r.name)) as dist return p,dist order by dist asc
1 2 3
match (n:`交通规划设计`{name:'项目名称'}),(m:`交通规划设计`{name:'设计速度'}) CALL apoc.algo.dijkstra(n,m,'RE','weight')yield path as path,weight as weight return path,weight
最短路径
1 2 3
match (n:`测试权重`{name:'项目名称'}),(m:`测试权重`{name:'设计速度'}), p=shortestpath((n)-[*..10]-(m)) RETURN p
所有路径
1 2 3 4 5
match (n:`测试权重`{name:'项目名称'}),(m:`测试权重`{name:'设计速度'}),
p=allshortestpaths((n)-[*..10]-(m))
RETURN p
多个节点两两间互相求最短路径
1 2 3 4 5 6 7 8 9
with ['项目名称','工可批复单位','设计速度'] as indicator_list match (n:`交通规划设计`) where n.name in indicator_list with collect(n) as nodes unwind nodes as source unwind nodes as target with source,target where id(source) match paths = shortestPath((source)-[*0..2]-(target)) with paths limit 20000 return paths
带条件的
1 2 3 4 5 6 7 8 9
with [3105, 200025928, 200025929, 151286502, 135660351] as id_list match (v:vertices) where v.id in id_list with collect(v) as nodes unwind nodes as source unwind nodes as target with source,target where id(source) match paths = shortestPath((source)-[:HOLDER|MANAGER*0..2]-(target)) where all(x in nodes(paths) where x.id<>3105) with paths limit 20000 return paths
多标签查询
1
match (n) where any(label in labels(n) WHERE label in ['A 标签', 'B 标签']) return n
查询字段类型
1 2
apoc.meta.type String cypher = "match(n:`zhctwh`) where apoc.meta.type(n.similar)='STRING' return n";




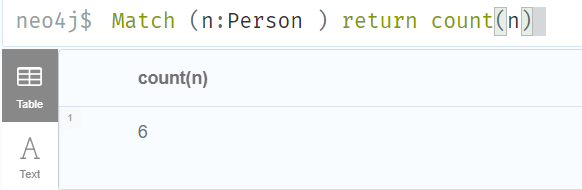
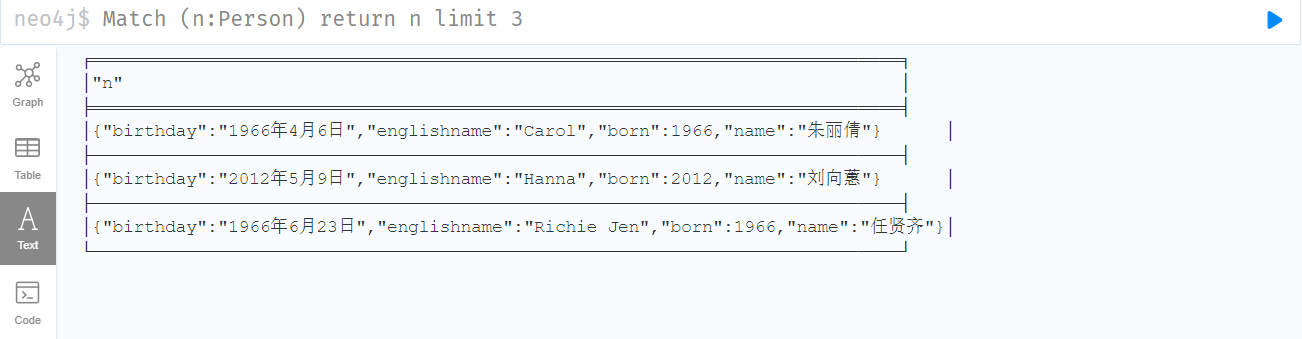
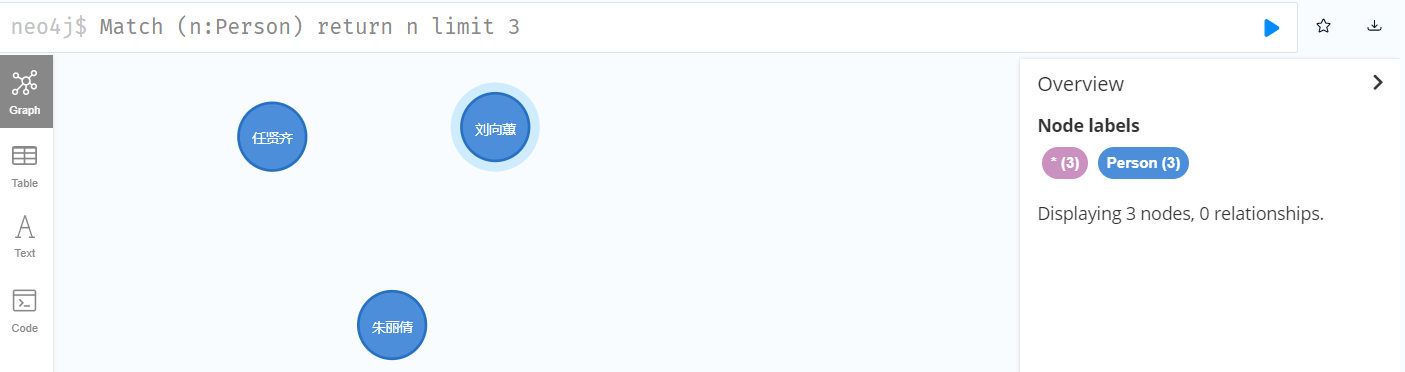
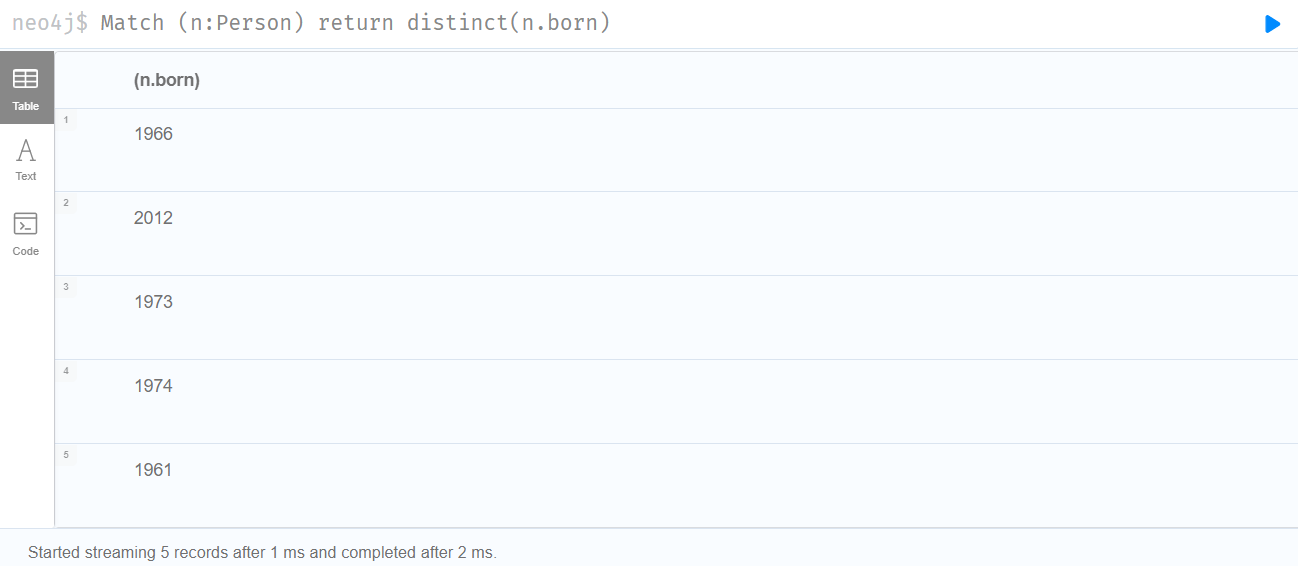

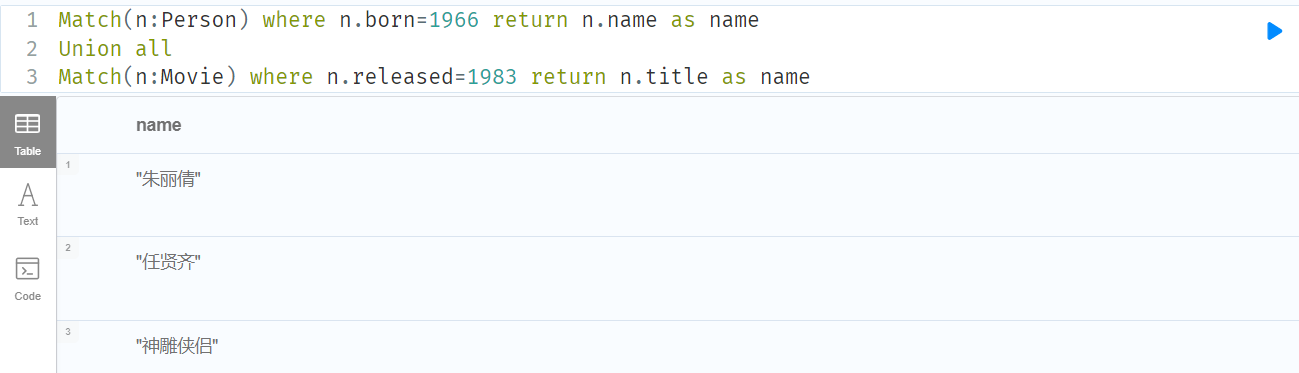
 6.10 Union all (Union)
6.10 Union all (Union)